1. MariaDB 설치·생성
1) MariaDB 설치

2) 데이터베이스 생성과 사용자 계정 추가
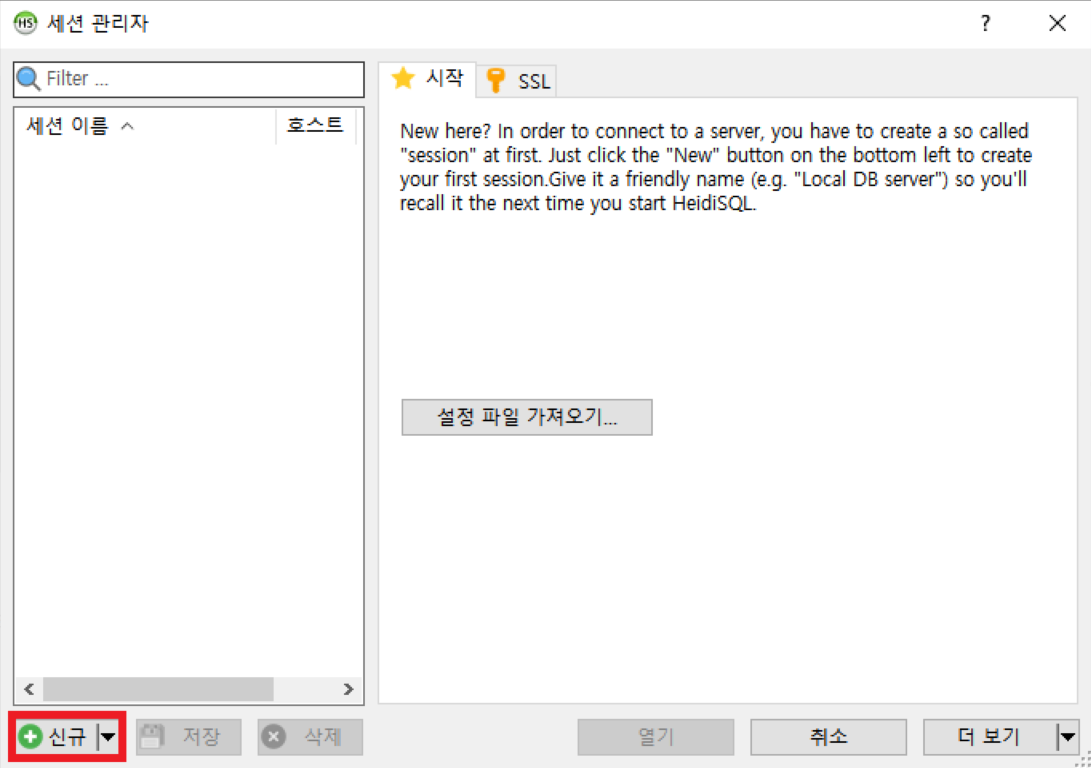
- 데이터베이스에서 필요한 작업을 명령하는 SQL 에디터인 HeidiSQL 프로그램이 같이 설치됨
- '신규 ' 버튼을 눌러서 root 계정으로 연결
- 설치할 때 지정했던 암호를 입력하고 열기

- 데이터베이스 생성


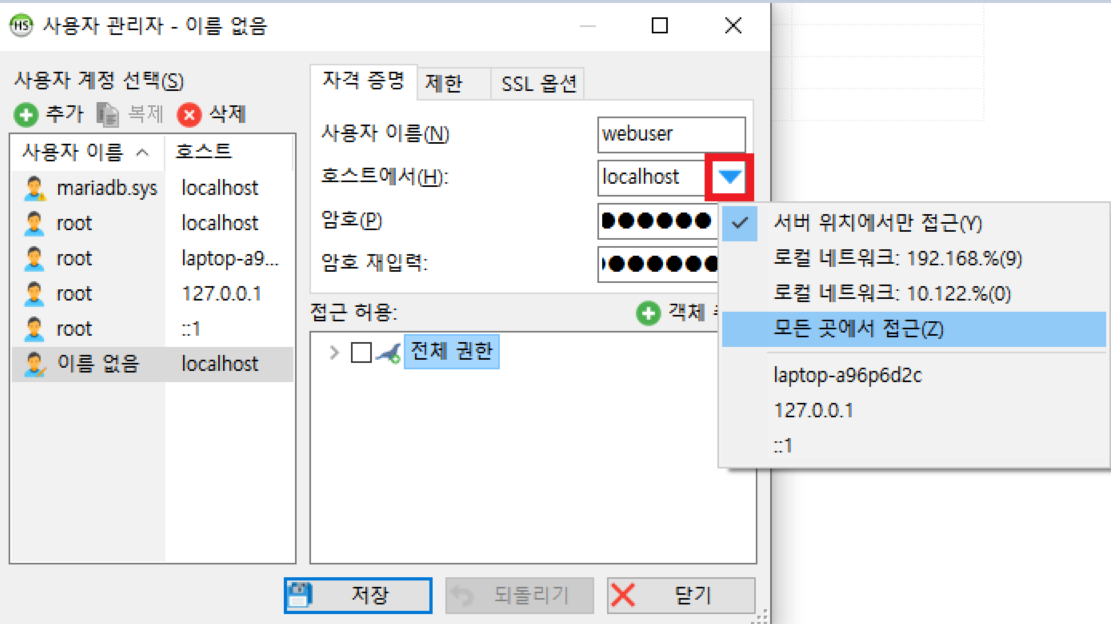
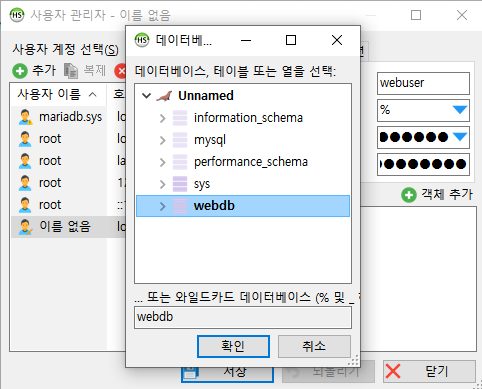
- 사용자 계정 생성과 권한 추가


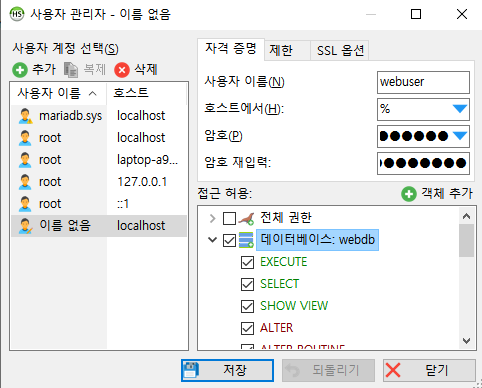
- 생성된 계정 확인



2. 프로젝트 생성과 MariaDB 준비
- 새로운 jdbcex 프로젝트 생성
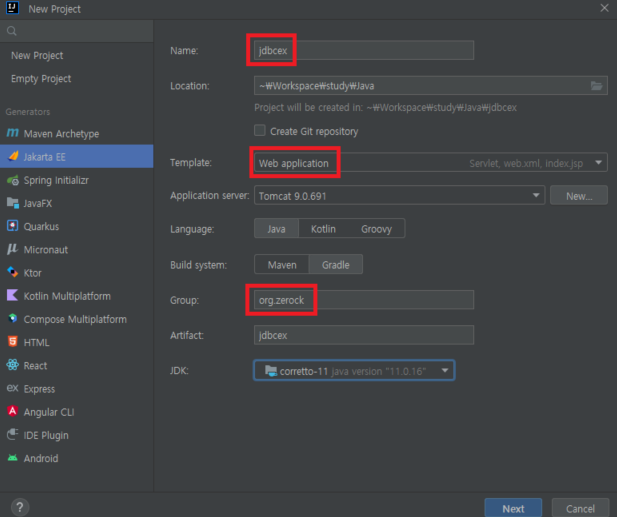
1) 인텔리제이의 MariaDB 설정

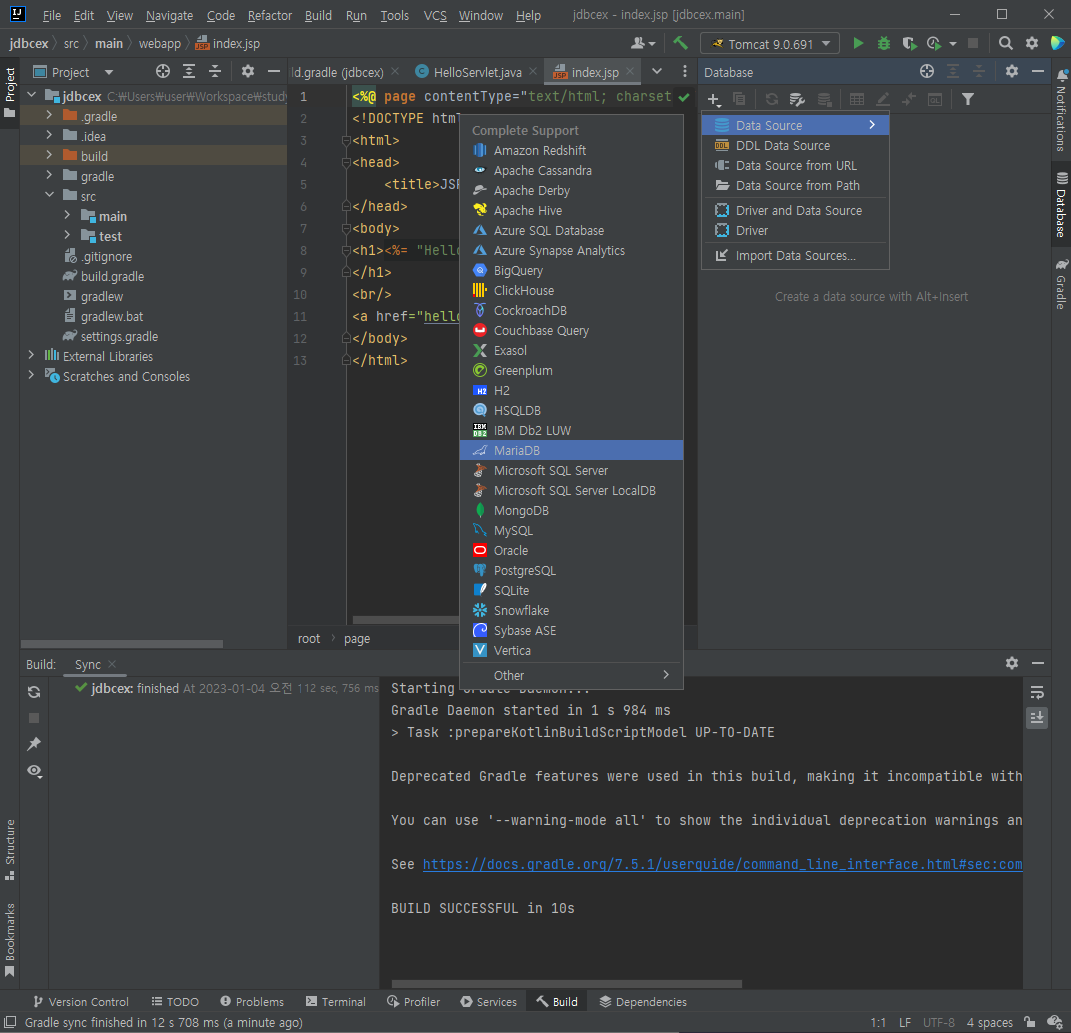

- 데이터베이스가 연동되면 생기는 SQL console 창에 현재 시간 테스트
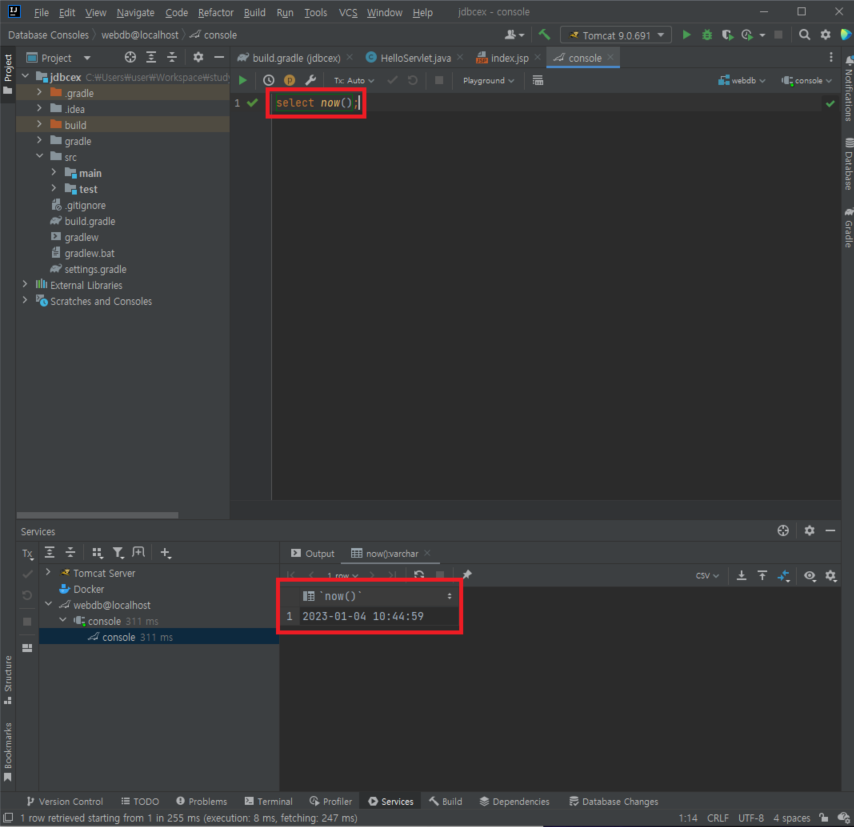
2) 프로젝트 내 MariaDB 설정
- 자바와 데이터베이스를 연동하기 위해 JDBC 드라이버라고 부르는 라이브러리 필요
- build.gradle에 설정 추가
- 구글에 'mariadb maven'을 검색하여 MariaDB Java Client에서 Gradle 또는 Gradle(Short의 내용을 복사하여 사용

- JDBC 프로그램의 구조
- JDBC는 Java Database Connectivity이 약자
- 자바 프로그램과 데이터베이스를 네트워크 상에서 연결해 데이터를 교환하는 프로그램
- 관련 API로 java.sql과 javax.sql 패키지 사용
3) JDBC 프로그램 작성 순서
- JDBC 프로그램은 네트워크를 통해 데이터베이스와 연결을 맺고, SQL을 전달해서 데이터베이스가 이를 실행하는 흐름
- 네트워크를 통해 데이터베이스와 연결을 맺는 단계
- 데이터베이스에서 보낼 SQL을 작성하고 전송하는 단계
- 필요하다면 데이터베이스가 보낸 결과를 받아서 처리하는 단계
- 데이터베이스와 연결을 종료하는 단계
- 실습_1. 테스트 프로그램 작성하기
// src > test > java > org.zerock.dao > ConnectTests
package org.zerock.dao;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
public class ConnectTests {
// Test를 적용하는 메서드는 반드시 public으로 선언, 파라미터나 return 없이 사용
@Test
public void test1() {
int v1 = 10;
int v2 = 10;
// 인자로 받은 두 변수의 값이 동일해야 test에 성공
Assertions.assertEquals(v1, v2);
}
}

- 이를 이용하여 MariaDB와의 연결을 확인하는 용도의 코드 작성
package org.zerock.dao;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectTests {
@Test
public void testConnection() throws Exception {
// JDBC 드라이버 클래스를 메모리상으로 로딩하는 역할
// 문자열은 패키지명과 클래스명의 대소문자까지 정확히 일치
Class.forName("org.mariadb.jdbc.Driver");
// java.sql 패키지의 Connection 인터페이스 타입의 변수
// 데이터베이스와의 네트워크 연결을 의미
Connection connection = DriverManager.getConnection(
// jdbc 프로토콜을 이용한다는 의미
// localhost:3306은 네트워크 연결정보,
// webdb는 연결하려는 데이터베이스 정보 의미
"jdbc:mariadb://localhost:3306/webdb",
// 연결을 위해 필요한 사용자 계정과 패스워드
"webuser",
"비밀번호");
// 데이터베이스와 정상적으로 연결이 된가면 Connection 타입의 객체는 null이 아니라는 것을 확신
Assertions.assertNotNull(connection);
// 작업이 완료되면 반드시 데이터베이스와의 연결을 종료
connection.close();
}
}
- 실습_2. 데이터베이스 테이블 생성
- 관계형 데이터베이스에서는 데이터 저장을 위해 테이블 생성
- 테이블은 여러 칼럼과 로우로 구성
- 각 칼럼에는 이름과 타입, 제약 조건 등이 결합
- MariaDB에서 사용하는 데이터 타입
| 타입 | 용도 | 크기 | 설명 |
|---|---|---|---|
| 숫자형 데이터 타입 | |||
| TINYINT | 매우 작은 정수 | 1 byte | -128 ~ 127 (부호 없이 0 ~ 255) |
| SMALLINT | 작은 정수 | 2 byte | -32768 ~ 32767 |
| MEDIUMINT | 중간 크기의 정수 | 3 byte | -(-8388608) ~ -1(8388607) |
| INT | 표준 정수 | 4 byte | -2147483648 ~ 2147483647 (부호 없이 0 ~ 4294967295) |
| BIGINT | 큰 정수 | 8 byte | -2147483648 ~ 2147483647 (부호 없이 0 ~ 4294967295) |
| FLOAT | 단정도 부동 소수 | 4 byte | -9223372036854775808 ~ 9223372036854775807 (부호 없이 0 ~ 18446744073709551615) |
| DOUBLE | 배정도 부동 소수 | 8 byte | -1.7976E+320 ~ -1.7976E+320 (부호 없이 쓸 수 없음) |
| DECIMAL(m, n) | 고정 소수 | m과 n에 따라 다름 | 숫자 데이터이지만 내부적으로 String 형태로 저장됨, 최개 65자 |
| BIT(n) | 비트 필드 | n에 따라 다름 | 1 ~ 64 bit 표현 |
| 날짜형 데이터 타입 | |||
| DATE | (형태)YYYY-MM-DD | 3 byte | 1000-01-01 ~ 9999-12-31 |
| DATETIME | (형태)YYYY-MM-DD hh:mm:ss |
8 byte | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP | (형태)YYYY-MM-DD hh:mm:ss |
4 byte | 1970-01-01 00:00:00 ~ 2037 |
| TIME | (형태)hh:mm:ss | 3 byte | -839:59:59 ~ 839:59:59 |
| YEAR | (형태)YYYY 또는 YY | 1 byte | 1901 ~ 2155 |
| 문자형 데이터 타입 | |||
| CHAR(n) | 고정 길이 비이진 문자열 | n byte | |
| VARCHAR(n) | 가변 길이 비이진 문자열 | Length + 1 byte | |
| BINARY(n) | 고정 길이 이진 문자열 | n byte | |
| VARBINARY(n) | 가변 길이 이진 문자열 | Length + 1 byte or 2 byte | |
| TINYBLOB | 매우 작은 Binary Large Object | Length + 1 byte | |
| BLOB | 작은 Binary Large Object | Length + 2 byte | 최대 크기 64KB |
| MEDIUMBLOB | 중간 크기 Binary Large Object | Length + 3 byte | 최대 크기 16MB |
| LONGBLOB | 큰 Binary Large Object | Length + 4 byte | 최대 크기 4GB |
| TINYTEXT | 매우 작은 비이진 문자열 | Length + 1 byte | |
| TEXT | 작은 비이진 문자열 | Length + 1 byte | 최대 크기 64KB |
| MEDIUMTEXT | 중간 크기 비이진 문자열 | Length + 3 byte | 최대 크기 16MB |
| LONGTEXT | 큰 비이진 문자열 | Length + 4 byte | 최대 크기 4GB |
- Todo 리스트를 저장하기 위한 테이블 생성
create table tbl_todo (
tno int auto_increment primary key,
title varchar(100) not null,
dueDate date not null,
finished tinyint default 0
);- tbl_todo라는 이름으로 생성
- tno는 primary key로 사용하며, auto_increment는 새로운 데이터 추가 시 자동으로 새로운 번호가 생성되도록 함
- dueDate는 '년-월-일'로 기록할 수 있는 date타입 이용
- MariaDB에서 boolean 값은 true / false 값 대신 0 / 1로 사용하는 경우가 많으므로 tinyint타입으로 처리

- 실습_3. 데이터 insert
- 데이터 추가
insert into tbl_todo (title, dueDate, finished)
values ('Test...', '2022-12-31', 1);

- 실습_4. 데이터 select
- 데이터 조회
- 'from'으로 데이터를 가져올 테이블 지정
- 'where로 조회할 데이터의 조건 지정
select * from tbl_todo where tno=1;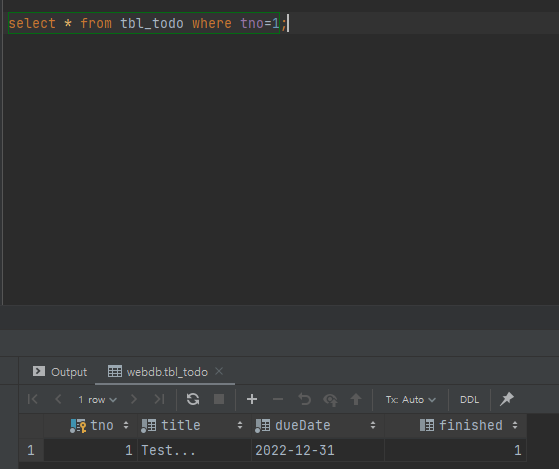
- 실습_5. 데이터 update
- 기존 데이터 수정
- 'set'으로 특정 칼럼 내용 수정
- 'where'로 수정할 데이터의 조건 지정
- 3번 데이터의 finished와 title 값을 변경하고 싶다면 아래의 코드 작성
update tbl_todo set finished = 0, title = 'Not Yet...' where tno = 3;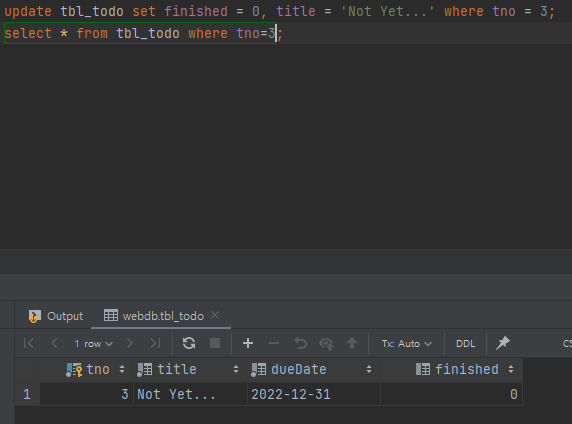
- 실습_6. 데이터 delete
- 데이터 삭제
- 'where ' 조건에 해당하는 데이터 삭제
- 'where' 조건이 없다면 모든 데이터 삭제할 수 있으므로 경고 메세지와 함께 실행되지 않음
- tno가 5보다 큰 데이터를 삭제하고 싶다면 아래의 코드 작성
delete from tbl_todo where tno > 5;
4) DML과 쿼리(select)의 차이
- DML(insert, update, delete)와 select의 차이
- DML은 몇 개의 데이터가 처리되었는지 숫자로 결과 반환
- select문은 데이터를 반환
- update문 실행 예시

- select문 실행 예시
select * from tbl_todo;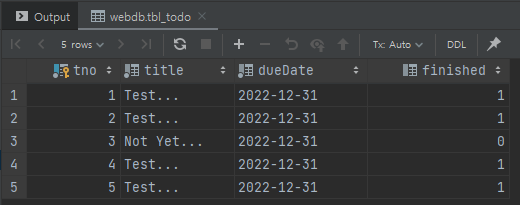
5) JDBC 프로그래밍을 위한 API와 용어들
- java.sql.Connection
- Connection 인터페이스는 데이터베이스와 네트워크 상의 연결을 의미
- 데이터베이스에 SQL을 실행하기 위해 반드시 정상적인 Connection 타입의 객체 생성해야 함
- 가장 중요한 사실은 "Connection은 반드시 close()해야 한다", 연결이 종료되지 않으면 새로운 연결을 받을 수 없는 상황이 발생함
- Connection 종료를 위해 try ~ catch ~ finally 또는 try-with-resource를 사용(후자 사용 시 자동으로 close()가 호출됨)
- 가장 중요한 기능은 Statement 혹은 Prepared-Statement 등 SQL을 실행할 수 있는 객체를 생성하는 기능
// Prepared-Statement 객체 생성 코드
Connection connection = ...
PreparedStatement preparedStatement = connection.preparedStatement("select * from tbl_todo");
- java.sql.Statement / PreparedStatement
- JDBC에서 SQL을 데이터베이스로 보내기 위해 Statement / PreparedStatement 타입 이용
- PreparedStatemetn는 SQL문을 미리 전달하고 나중에 데이터를 보내는 방식
- Statement는 SQL문 내부에서 모든 데이터를 같이 전송하는 방식
- 실제 개발에서는 SQL 내부에 고의적으로 다른 SQL 문을 심는 SQL injection을 막기 위해 PreparedStatement만 사용
- Statement / PreparedStatement의 주요 기능
- setXXX(): setInt(), setString(), setDate()와 같이 다양한 타입에 맞게 데이터 세팅
- executeUpdate(): DML을 실행하고 결과를 int 타입으로 반환(몇 행이 영향을 받았는지)
- executeQuery(): 쿼리(select)를 실행할 때 사용, ResultSet이라는 return 타입 이용
- Statement도 Connection처럼 마지막에 close() 해주어야, 데이터베이스 내부에서도 메모리와 같이 사용했던 자원들이 즉각 정리됨
- java.sql.ResultSet
- 쿼리(select)를 실행했을 때 반환하는 데이터를 읽어들이기 위한 인터페이스
- 자바 코드에서 데이터를 읽어 들이기 때문에 getInt(), getString() 등의 메서드를 이용해서 필요한 타입으로 데이터를 읽어 들임
- ResultSet의 메서드 next(): ResultSet은 데이터를 순차적으로 읽는 방식으로 구성되기 때문에 next()를 이용해 다음 행의 데이터를 읽을 수 있도록 이동하는 작업이 필요
- ResultSet 역시 마지막에 close() 해주어야 데이터베이스에서 자원을 즉각 회수
- Connection Pool과 DataSource
- JDBC 프로그램은 기본적으로 필요한 순간 잠깐 데이터베이스과 네트워크로 연결하고 데이터를 주고 받는 방식
- 이 과정에서 데이터베이스와 연결을 맺는 작업은 많은 시간과 자원을 쓰므로 SQL을 여러 번 실행하면 성능 저하
- 이 때, Connection Pool을 이용하여 문제 해결
- Connection Pool: 미리 Connection들을 생성해 보관, 필요할 때 꺼내 쓰는 방식
- javax.sql.DataSource 인터페이스는 Connection Pool을 자바에서 API 형태로 지원
- Connection Pool은 이미 작성된 라이브러리 이용(DBCP, C3PO, HikariCP 등)
- DAO(Data Access Object)
- 데이터를 전문적으로 처리하는 객체
- 데이터베이스의 접근과 처리를 전담하는 객체이고, 주로 VO(Value Object, 읽을 수 있는 값) 단위로 처리
- DAO를 호출하는 객체는 DAO 내부에서 어떤 식으로 데이터를 처리하는지 알 수 없도록 구성
- VO(Value Object) 혹은 엔티티(Entity)
- 객체지향 프로그램은 데이터를 객체 단위로 처리(ex)테이블 한 행이 자바 프로그램에서 하나의 객체)
- 데이터베이스에서는 하나의 데이터를 하나의 엔티티라고 하며 자바 프로그램은 이를 처리하기 위해 테이블과 유사한 구조의 클래스를 만들어 객체로 처리
- 이때 만든 객체는 값을 보관하는 용도라는 의미에서 VO라고 함
- DTO는 각 계층을 오고 가는데 사용되는 택배 상자와 비슷 / VO는 데이터베이스의 엔티티를 자바 객체로 표현
- DTO는 getter / setter를 이용해 자유롭게 데이터 가공 / VO는 주로 데이터 자체를 의미하므로 getter만 사용
'back-end > Java' 카테고리의 다른 글
| [자바 웹 개발 워크북] 2.3 - 웹 MVC와 JDBC의 결합 (1) | 2023.01.06 |
|---|---|
| [자바 웹 개발 워크북] 2.2 - 프로젝트 내 JDBC 구현 (0) | 2023.01.05 |
| [자바 웹 개발 워크북] 1.5 - 모델(Model) (0) | 2023.01.03 |
| [자바 웹 개발 워크북] 1.4 - HttpServlet (0) | 2023.01.02 |
| [자바 웹 개발 워크북] 1.3 - Web MVC 방식 (0) | 2022.12.30 |