● 나이브 베이즈 분류기(Naive Bayes Classification)
- 베이즈 정리를 적용한 확률적 분류 알고리즘
- 오든 특성들이 독립임(naive임)을 가정
- 입력 특성에 따라 3개의 분류기 존재
- 가우시안 나이브 베이즈 분류기
- 베르누이 나이브 베이즈 분류기
- 다항 나이브 베이즈 분류기
1. 나이브 베이즈 분류기의 확률 모델
- 나이브 베이즈는 조건부 확률 모델
- N개의 특성을 나타내는 벡터 x를 입력 받아 k개의 가능한 확률적 결과를 출력
$$ p(C_{k}|x_{1},\cdots,x_{n}) $$
- 위의 식에 베이즈 정리를 적용하면 다음과 같음
$$ p(C_{k}|\textrm{x})=\frac{p(C_{k})p(\textrm{x}|C_{k})}{p(\textrm{x})} $$
- 위의 식에서 분자만이 출력 값에 영향을 받기 때문에 분모 부분을 상수로 취급할 수 있음
$$ \begin{align*} p(C_{k}|\textrm{x})&\propto p(C_{k})p(\textrm{x}|C_{k})\\
&\propto p(C_{k},x_{1},\cdots,x_{n}) \end{align*} $$
- 위의 식을 연쇄 법칙을 사용해 다음과 같이 쓸 수 있음
$$ \begin{align*} p(C_{k}, x_{1},\cdots, x_{n}) &=P(C_{k})p(x_{1},\cdots,x_{n}|C_{k})\\ &=P(C_{k})p(x_{1}|C_{k})p(x_{2},\cdots,x_{n}|C_{k}, x_{1})\\ &=P(C_{k})p(x_{1}|C_{k})p(x_{2}|C_{k},x_{1})p(x_{3},\cdots,x_{n}|C_{k}, x_{1}, x_{2})\\ &=P(C_{k})p(x_{1}|C_{k})p(x_{2}|C_{k},x_{1})\cdots p(x_{n}|C_{k}, x_{1}, x_{2},\cdots ,x_{n-1}) \end{align*} $$
- 나이브 베이즈 분류기는 모든 특성이 독립이라고 가정하여 위의 식을 다음과 같이 쓸 수 있음
$$ \begin{align*} p(C_{k}, x_{1}, \cdots ,x_{n}) & \propto p(C_{k})p(x_{1}|C_{k})p(x_{2}|C_{k}) \cdots p(x_{n}|C_{k})\\ &\propto p(C_{k})\prod_{i=1}^{n}p(x_{i}|C_{k}) \end{align*} $$
- 위의 식을 통해 나온 값들 중 가장 큰 값을 갖는 클래스가 예측 결과
$$ \hat{y}=\underset{k}{\textrm{argmax}}\,\, p(C_{k})\prod_{i=1}^{n}p(x_{i}|C_{k}) $$
# 계산 원리
# p(C_k) 부분
prior = [0.45, 0.3, 0.15, 0.1]
# 가능성(확률)
likelihood = [[0.3, 0.3, 0.4], [0.7, 0.2, 0.1], [0.15, 0.5, 0.35], [0.6, 0.2, 0.2]]
# 각 prior에 대한 가능성의 계산을 합한 결과
idx = 0
for c, xs in zip(prior, likelihood):
result = 1
for x in xs:
result *=x
result *= c
idx += 1
print(f"{idx}번째 클래스의 가능성: {result}")
# 출력 결과
# 0.3 * 0.3 * 0.4 * 0.45
1번째 클래스의 가능성: 0.0162
# 0.7 * 0.2 * 0.1 * 0.3
2번째 클래스의 가능성: 0.0042
# 0.15 * 0.5 * 0.35 * 0.15
3번째 클래스의 가능성: 0.0039375
# 0.6 * 0.2 * 0.2 * 0.1
4번째 클래스의 가능성: 0.0024000000000000002
1) 산림 토양 데이터
import numpy as np
import pandas as pd
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
from sklearn.datasets import fetch_covtype, fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import CountVectorizer, HashingVectorizer, TfidfVectorizer
from sklearn import metricscovtype = fetch_covtype()
print(covtype.DESCR)
# 출력 결과
...
**Data Set Characteristics:**
================= ============
Classes 7 # 7개의 토양 클래스
Samples total 581012
Dimensionality 54 # 특성 변수 54개
Features int
================= ============
...# 학습, 평가 데이터 분류
covtype_X = covtype.data
covtype_y = covtype.target
covtype_X_train, covtype_X_test, covtype_y_train, covtype_y_test = train_test_split(covtype_X, covtype_y, test_size = 0.2)
print("전체 데이터 크기: {}".format(covtype_X.shape))
print("학습 데이터 크기: {}".format(covtype_X_train.shape))
print("평가 데이터 크기: {}".format(covtype_X_test.shape))
# 출력 결과
전체 데이터 크기: (581012, 54)
학습 데이터 크기: (464809, 54)
평가 데이터 크기: (116203, 54)
- 전처리
scaler = StandardScaler()
covtype_X_train_scale = scaler.fit_transform(covtype_X_train)
covtype_X_test_scale = scaler.transform(covtype_X_test)
- 가우시안 나이브 베이즈
model = GaussianNB()
model.fit(covtype_X_train_scale, covtype_y_train)
# train 데이터
predict = model.predict(covtype_X_train_scale)
acc = metrics.accuracy_score(covtype_y_train, predict)
f1 = metrics.f1_score(covtype_y_train, predict, average = None)
print("Accuracy: {}".format(acc))
print("F1 score: {}".format(f1))
# 출력 결과
Accuracy: 0.0879328928656717
F1 score: [0.0400872 0.0179923 0.33471803 0.1384795 0.04347626 0.07084596
0.23590156]
# test 데이터
predict = model.predict(covtype_X_test_scale)
acc = metrics.accuracy_score(covtype_y_test, predict)
f1 = metrics.f1_score(covtype_y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.08831957866836485
Test F1 score: [0.04190772 0.01778446 0.33599527 0.13787086 0.04217007 0.06545961
0.23676243]# 시각화(데이터가 크므로 make_blobs로 임의의 데이터 만들어서 연습)
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
def make_meshgrid(x, y, h = .02):
x_min, x_max = x.min()-1, x.max()+1
y_min, y_max = y.min()-1, y.max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contours(clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = plt.contourf(xx, yy, Z, **params)
return out
X, y = make_blobs(n_samples = 1000)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')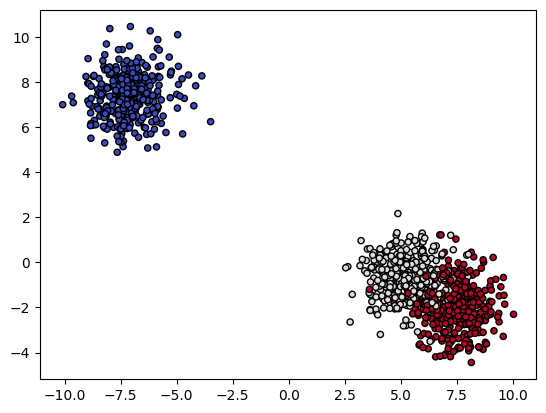
model = GaussianNB()
model.fit(X, y)
xx, yy = make_meshgrid(X[:, 0], X[:, 1])
plot_contours(model, xx, yy, cmap = plt.cm.coolwarm, alpha = 0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
# 시각화(실제 토양 데이터)
plt.scatter(covtype_X[:, 0], covtype_X[:, 1], c = covtype_y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')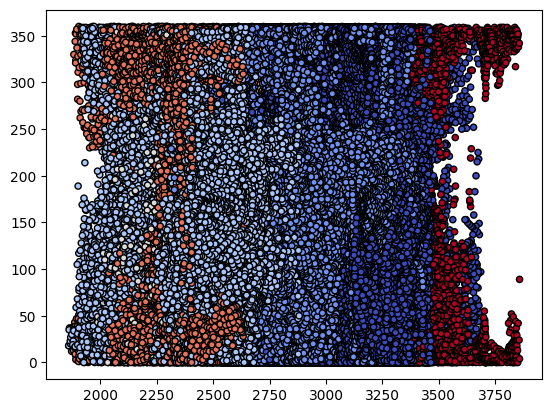
2) 뉴스 데이터
newsgroup = fetch_20newsgroups()
print(newsgroup.DESCR)
# 출력 결과
...
**Data Set Characteristics:**
================= ==========
Classes 20 # 20개의 클래스
Samples total 18846
Dimensionality 1 # 변수가 1개
Features text
================= ==========
...# 학습, 평가 데이터 분류
newsgroup_train = fetch_20newsgroups(subset = 'train')
newsgroup_test = fetch_20newsgroups(subset = 'test')
X_train, y_train = newsgroup_train.data, newsgroup_train.target
X_test, y_test = newsgroup_test.data, newsgroup_test.target
- 벡터화
- 텍스트 데이터는 기계학습 모델에 입력할 수 없음
- 벡터화는 텍스트 데이터를 실수 벡터로 변환해 기계학습 모델에 입력할 수 있도록 하는 전처리 과정
- scikit-learn에서는 Count, Tf-idf, Hashing 세가지 방법 지원
- CounterVectorize
- 가장 간단한 형태
- 문서에 나온 단어의 수를 세서 벡터 생성
count_vectorizer = CountVectorizer()
X_train_count = count_vectorizer.fit_transform(X_train)
X_test_count = count_vectorizer.transform(X_test)
# 데이터를 희소 행렬(sparce matrix) 형태로 표현
X_train_count
# 출력 결과
<11314x130107 sparse matrix of type '<class 'numpy.int64'>'
with 1787565 stored elements in Compressed Sparse Row format># 첫번째 데이터에 대해 각 단어의 개수 출력
for v in X_train_count[0]:
print(v)
- HashingVectorizer
- 각 단어를 해쉬 값으로 표현
- 미리 정해진 크기의 벡터로 표현
# 제한된 크기(n_features)의 벡터를 가짐
hash_vectorizer = HashingVectorizer(n_features = 1000)
X_train_hash = hash_vectorizer.fit_transform(X_train)
X_test_hash = hash_vectorizer.transform(X_test)
# 마찬가지로 희소 행렬 형태
X_train_hash
# 출력 결과
<11314x1000 sparse matrix of type '<class 'numpy.float64'>'
with 1550687 stored elements in Compressed Sparse Row format># 해쉬값 형태로 출력됨
for v in X_train_hash[0]:
print(v)
- TfIdfVectorizer
- 문서에 나온 단어 빈도(term frequency)와 역문서 빈도(inverse document frequency)를 곱해서 구함
- 각 빈도는 일반적으로 로그 스케일링 후 사용
- \( tf(t, d)=log(f(t,d)+1) \)
- \( idf(t, D)=\frac{|D|}{|d\in D:t \in d|+1} \)
- \( tfidf(t, d, D)=tf(t, d) \times idf(t, D) \)
tfidf_vectorizer = TfidfVectorizer()
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
X_train_tfidf
# 출력 결과
<11314x130107 sparse matrix of type '<class 'numpy.float64'>'
with 1787565 stored elements in Compressed Sparse Row format># Tf-Idf 값으로 출력
for v in X_train_tfidf[0]:
print(v)
- 베르누이 나이브 베이즈: 입력 특성이 베르누이 분포에 의해 생성된 이진 값을 갖는다고 가정
model = BernoulliNB()
# CountVextorizer로 벡터화한 모델
model.fit(X_train_count, y_train)
# 훈련 데이터
model = BernoulliNB()
model.fit(X_train_count, y_train)
# 출력 결과
Train Accuracy: 0.7821283365741559
Train F1 score: [0.80096502 0.8538398 0.13858268 0.70686337 0.85220126 0.87944493
0.51627694 0.84532672 0.89064976 0.87179487 0.94561404 0.91331546
0.84627832 0.89825848 0.9047619 0.79242424 0.84693878 0.84489796
0.67329545 0.14742015]
# 테스트 데이터
predict = model.predict(X_test_count)
acc = metrics.accuracy_score(y_test, predict)
f1 = metrics.f1_score(y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.6307753584705258
Test F1 score: [0.47086247 0.60643564 0.01 0.56014047 0.6953405 0.70381232
0.44829721 0.71878646 0.81797753 0.81893491 0.90287278 0.74794521
0.61647059 0.64174455 0.76967096 0.63555114 0.64285714 0.77971474
0.31382979 0.00793651]# HashingVectorizer로 벡터화한 모델
model.fit(X_train_hash, y_train)
# 훈련 데이터
predict = model.predict(X_train_hash)
acc = metrics.accuracy_score(y_train, predict)
f1 = metrics.f1_score(y_train, predict, average = None)
print("Train Accuracy: {}".format(acc))
print("Train F1 score: {}".format(f1))
# 출력 결과
Train Accuracy: 0.5951917977726711
Train F1 score: [0.74226804 0.49415205 0.45039019 0.59878155 0.57327935 0.63929619
0.35390947 0.59851301 0.72695347 0.68123862 0.79809524 0.70532319
0.54703833 0.66862745 0.61889927 0.74707471 0.6518668 0.60485269
0.5324165 0.54576271]
# 테스트 데이터
predict = model.predict(X_test_hash)
acc = metrics.accuracy_score(y_test, predict)
f1 = metrics.f1_score(y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.4430430164630908
Test F1 score: [0.46678636 0.33826638 0.29391892 0.45743329 0.41939121 0.46540881
0.34440068 0.46464646 0.62849873 0.53038674 0.63782051 0.55251799
0.32635983 0.34266886 0.46105919 0.61780105 0.46197991 0.54591837
0.27513228 0.3307888 ]# TfIdfVectorizer로 벡터화한 모델
model.fit(X_train_tfidf, y_train)
# 훈련 데이터
predict = model.predict(X_train_tfidf)
acc = metrics.accuracy_score(y_train, predict)
f1 = metrics.f1_score(y_train, predict, average = None)
print("Train Accuracy: {}".format(acc))
print("Train F1 score: {}".format(f1))
# 출력 결과
Train Accuracy: 0.7821283365741559
Train F1 score: [0.80096502 0.8538398 0.13858268 0.70686337 0.85220126 0.87944493
0.51627694 0.84532672 0.89064976 0.87179487 0.94561404 0.91331546
0.84627832 0.89825848 0.9047619 0.79242424 0.84693878 0.84489796
0.67329545 0.14742015]
# 테스트 데이터
predict = model.predict(X_test_tfidf)
acc = metrics.accuracy_score(y_test, predict)
f1 = metrics.f1_score(y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.6307753584705258
Test F1 score: [0.47086247 0.60643564 0.01 0.56014047 0.6953405 0.70381232
0.44829721 0.71878646 0.81797753 0.81893491 0.90287278 0.74794521
0.61647059 0.64174455 0.76967096 0.63555114 0.64285714 0.77971474
0.31382979 0.00793651]- 시각화
# 시각화(데이터가 크므로 make_blobs로 임의의 데이터 만들어서 연습)
X, y = make_blobs(n_samples = 1000)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
model = BernoulliNB()
model.fit(X, y)
xx, yy = make_meshgrid(X[:, 0], X[:, 1])
plot_contours(model, xx, yy, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')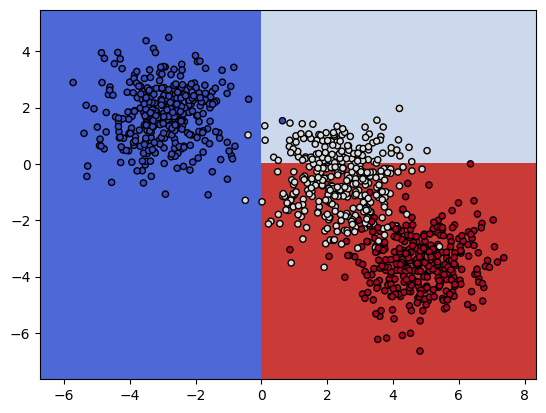
- 다항 나이브 베이즈: 입력 특성이 다항분포에 의해 생성된 빈도수 값을 갖는다고 가정
model = MultinomialNB()
# CountVectorizer로 벡터화한 모델
model.fit(X_train_count, y_train)
# 훈련 데이터
predict = model.predict(X_train_count)
acc = metrics.accuracy_score(y_train, predict)
f1 = metrics.f1_score(y_train, predict, average = None)
print("Train Accuracy: {}".format(acc))
print("Train F1 Score: {}".format(f1))
# 출력 결과
Train Accuracy: 0.9245182959165635
Train F1 Score: [0.95228426 0.904 0.25073746 0.81402003 0.96669513 0.88350983
0.90710383 0.97014925 0.98567818 0.99325464 0.98423237 0.95399516
0.95703454 0.98319328 0.98584513 0.95352564 0.97307002 0.97467249
0.95157895 0.86526946]
# 테스트 데이터
predict = model.predict(X_test_count)
acc = metrics.accuracy_score(y_test, predict)
f1 = metrics.f1_score(y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 Score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.7728359001593202
Test F1 Score: [0.77901431 0.7008547 0.00501253 0.64516129 0.79178082 0.73370166
0.76550681 0.88779285 0.93951094 0.91390728 0.94594595 0.78459938
0.72299169 0.84635417 0.86029412 0.80846561 0.78665077 0.89281211
0.60465116 0.48695652]# TdIdfVectorizer로 벡터화한 모델
model.fit(X_train_tfidf, y_train)
# 훈련 데이터
predict = model.predict(X_train_tfidf)
acc = metrics.accuracy_score(y_train, predict)
f1 = metrics.f1_score(y_train, predict, average = None)
print("Train Accuracy: {}".format(acc))
print("Train F1 Score: {}".format(f1))
# 출력 결과
Train Accuracy: 0.9326498143892522
Train F1 Score: [0.87404162 0.95414462 0.95726496 0.92863002 0.97812773 0.97440273
0.91090909 0.97261411 0.98659966 0.98575021 0.98026316 0.94033413
0.9594478 0.98032506 0.97755611 0.77411003 0.93506494 0.97453907
0.90163934 0.45081967]
# 테스트 데이터
predict = model.predict(X_test_tfidf)
acc = metrics.accuracy_score(y_test, predict)
f1 = metrics.f1_score(y_test, predict, average = None)
print("Test Accuracy: {}".format(acc))
print("Test F1 Score: {}".format(f1))
# 출력 결과
Test Accuracy: 0.7738980350504514
Test F1 Score: [0.63117871 0.72 0.72778561 0.72104019 0.81309686 0.81643836
0.7958884 0.88135593 0.93450882 0.91071429 0.92917167 0.73583093
0.69732938 0.81907433 0.86559803 0.60728118 0.76286353 0.92225201
0.57977528 0.24390244]- 시각화
# 시각화(데이터가 크므로 make_blobs로 임의의 데이터 만들어서 연습)
from sklearn.preprocessing import MinMaxScaler
X, y = make_blobs(n_samples = 1000)
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
model = MultinomialNB()
model.fit(X, y)
xx, yy = make_meshgrid(X[:, 0], X[:, 1])
plot_contours(model, xx, yy, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
'Python > Machine Learning' 카테고리의 다른 글
| [머신러닝 알고리즘] 결정 트리 (0) | 2023.01.18 |
|---|---|
| [머신러닝 알고리즘] 서포트 벡터 머신 (0) | 2023.01.13 |
| [머신러닝 알고리즘] K 최근접 이웃 (0) | 2023.01.10 |
| [머신러닝 알고리즘] 로지스틱 회귀 (0) | 2023.01.04 |
| [머신러닝 알고리즘] 선형 회귀(2) (0) | 2023.01.02 |