● 서포트 벡터 머신(Support Vector Machine)
- 회귀, 분류, 이상치 탐지 등에 사용되는 지도 학습 방법
- 서포트 벡터: 클래스 사이의 경계에 위치한 데이터 포인트
- 각 서포트 벡터가 클래스 사이의 경계를 구분하는데 얼마나 중요한지 학습
- 각 서포트 벡터 사이의 margin이 가장 큰 방향으로 학습
- 서포트 벡터까지의 거리와 서포트 벡터의 중요도를 기반으로 예측 수행
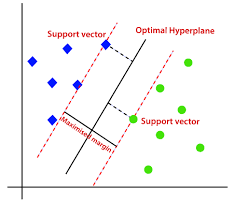
- SVM을 사용한 회귀 모델(SVR)
X, y = load_diabetes(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
model = SVR()
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.14990303611569455
평가 데이터 점수: 0.18406447674692128- SVM을 사용한 분류 모델(SVC)
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
model = SVC()
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9107981220657277
평가 데이터 점수: 0.951048951048951
1. 커널 기법
- 입력 데이터를 고차원 공간에 사상(Mapping)하여 비선형 특징을 학습할 수 있도록 확장
- scikit-learn에서는 Linear, Polynomial, RBF(Radial Basis Function) 등 다양한 커널 기법 지원

- 위의 두 개는 Linear Kernel로, 직선으로 분류
- 아래는 RBF Kernel과 Polynomial Kernel로 비선형적으로 분류
# SVR에 대해 Linear, Polynomial, RBF Kernel 각각 적용
X, y = load_diabetes(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
linear_svr = SVR(kernel = 'linear')
linear_svr.fit(X_train, y_train)
print("Linear SVR 학습 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
print("Linear SVR 평가 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
polynomial_svr = SVR(kernel = 'poly')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVR 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVR 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
rbf_svr = SVR(kernel = 'rbf')
rbf_svr.fit(X_train, y_train)
print("RBF SVR 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVR 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
Linear SVR 학습 데이터 점수: -0.0029544543016808422
Linear SVR 평가 데이터 점수: -0.0029544543016808422
Polynomial SVR 학습 데이터 점수: 0.26863144203680633
Polynomial SVR 평가 데이터 점수: 0.26863144203680633
RBF SVR 학습 데이터 점수: 0.14990303611569455
RBF SVR 평가 데이터 점수: 0.14990303611569455# SVC에 대해 Linear, Polynomial, RBF Kernel 각각 적용
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
linear_svr = SVC(kernel = 'linear')
linear_svr.fit(X_train, y_train)
print("Linear SVC 학습 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
print("Linear SVC 평가 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
polynomial_svr = SVC(kernel = 'poly')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVC 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVC 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
rbf_svr = SVC(kernel = 'rbf')
rbf_svr.fit(X_train, y_train)
print("RBF SVC 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVC 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
Linear SVC 학습 데이터 점수: 0.9694835680751174
Linear SVC 평가 데이터 점수: 0.9694835680751174
Polynomial SVC 학습 데이터 점수: 0.8990610328638498
Polynomial SVC 평가 데이터 점수: 0.8990610328638498
RBF SVC 학습 데이터 점수: 0.9107981220657277
RBF SVC 평가 데이터 점수: 0.9107981220657277
2. 매개변수 튜닝
- SVM은 사용하는 Kernel에 따라 다양한 매개변수 설정 가능
- 매개변수를 변경하면서 성능 변화를 관찰
# SVC의 Polynomial Kernel 설정에서 매개변수를 더 변경
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
polynomial_svr = SVC(kernel = 'poly', degree = 2, C = 0.1, gamma = 'auto')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVC 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVC 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
# 출력 결과
Polynomial SVC 학습 데이터 점수: 0.9765258215962441
Polynomial SVC 평가 데이터 점수: 0.9765258215962441
# SVC의 RBF Kernel 설정에서 매개변수를 더 변경
rbf_svr = SVC(kernel = 'rbf', C = 2.0, gamma = 'scale')
rbf_svr.fit(X_train, y_train)
print("RBF SVC 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVC 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
RBF SVC 학습 데이터 점수: 0.9131455399061033
RBF SVC 평가 데이터 점수: 0.9131455399061033- 위에서 기본 매개변수로만 돌렸을 때 0.89정도로 나왔던 점수보다 더 높은 점수로, 매개변수를 조작함에 따라 성능이 더 높아짐을 확인
3. 데이터 전처리
- SVM은 입력 데이터가 정규화 되어야 좋은 성능을 보임
- 주로 모든 특성 값의 범위를 [0, 1]로 맞추는 방법 사용
- scikit-learn의 StandardScaler 또는 MinMaxScaler 사용해 정규화
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
# 스케일링 이전 데이터
model = SVC()
model.fit(X_train, y_train)
print("SVC 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVC 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVC 학습 데이터 점수: 0.9107981220657277
SVC 평가 데이터 점수: 0.951048951048951
# 스케일링 이후 데이터
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model.fit(X_train, y_train)
print("SVC 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVC 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVC 학습 데이터 점수: 0.9882629107981221
SVC 평가 데이터 점수: 0.972027972027972
4. 당뇨병 데이터로 SVR(커널은 기본값('linear')로) 실습
- 가장 기본 모델
# 데이터 불러오기
X, y = load_diabetes(return_X_y = True)
# 학습 / 평가 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# 범위 [0, 1]로 정규화
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 선형 SVR 모델에 피팅
model = SVR(kernel = 'linear')
model.fit(X_train, y_train)
# 점수 출력
print("SVR 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVR 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVR 학습 데이터 점수: 0.5114667038352527
SVR 평가 데이터 점수: 0.45041670810045853
- 차원 변환
X_comp = TSNE(n_components = 1).fit_transform(X)
plt.scatter(X_comp, y)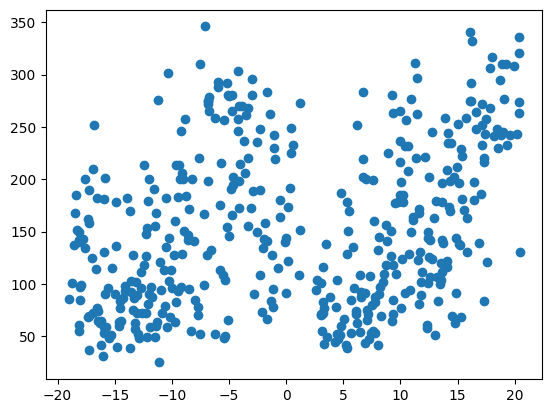
model.fit(X_comp, y)
# 선형으로 예측한 값
predict = model.predict(X_comp)
plt.scatter(X_comp, y)
plt.scatter(X_comp, predict, color = 'r')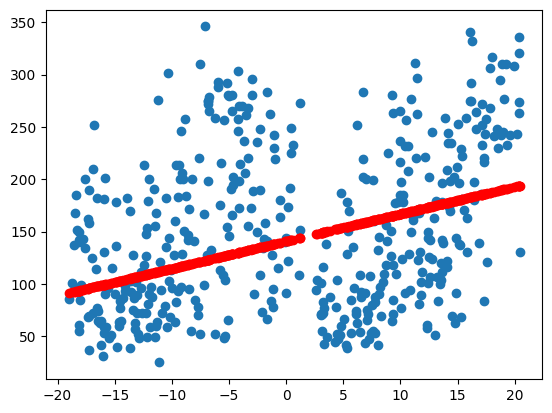
- 파이프라인으로 하나로 묶기
estimator = make_pipeline(StandardScaler(), SVR(kernel = 'linear'))
cross_validate(
estimator = estimator,
X = X, y = y,
cv = 5,
n_jobs = multiprocessing.cpu_count(),
verbose = True
)
# 출력 결과
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 2 out of 5 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=8)]: Done 5 out of 5 | elapsed: 0.5s finished
{'fit_time': array([0.00697613, 0.00797367, 0.00599027, 0.00797415, 0.00897002]),
'score_time': array([0.00099683, 0.00099564, 0.00099587, 0.00099683, 0.00099707]),
'test_score': array([0.43039087, 0.51655019, 0.48275821, 0.4224617 , 0.53077081])}
- GridSearch까지 포함
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'linear'))])
param_grid = [{'model__gamma': ['scale', 'auto'],
'model__C': [1.0, 0.1, 0.01],
'model__epsilon': [1.0, 0.1, 0.01]}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# epsilon이 1.0일 때 가장 좋은 예측
5. 당뇨병 데이터로 SVR(커널 변경) 실습
# 하이퍼 파라미터에 kernel을 넣어 어떤 kernel이 가장 좋은 지 판단
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'rbf'))])
param_grid = [{'model__kernel': ['rbf', 'poly', 'sigmoid']}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# sigmoid가 가장 좋은 예측을 하는 것으로 나옴
# 커널은 sigmoid로 하고 나머지 하이퍼 파라미터 중 어떤 게 좋은지 GridSearch 실행
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'sigmoid'))])
param_grid = [{'model__gamma': ['scale', 'auto'],
'model__C': [1.0, 0.1, 0.01],
'model__epsilon': [1.0, 0.1, 0.01]}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# epsilon이 1.0, gamma는 auto일 때 가장 좋음
- 최종 sigmoid를 사용한 점수
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.3649291208855052
평가 데이터 점수: 0.39002165443861103
6. 유방암 데이터로 SVC(커널은 기본값('linear')로) 실습
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = SVC(kernel = 'linear')
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9846153846153847
평가 데이터 점수: 1.0- 이미 잘 나오긴 함
- 시각화
def make_meshgrid(x, y, h = 0.02):
x_min, x_max = x.min()-1, x.max()+1
y_min, y_max = y.min()-1, y.max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contour(clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = plt.contourf(xx, yy, Z, **params)
return out
X_comp = TSNE(n_components = 2).fit_transform(X)
X0, X1 = X_comp[:, 0], X_comp[:, 1]
xx, yy = make_meshgrid(X0, X1)
model.fit(X_comp, y)
plot_contour(model, xx, yy, cmap = plt.cm.coolwarm, alpha = 0.7)
plt.scatter(X0, X1, c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')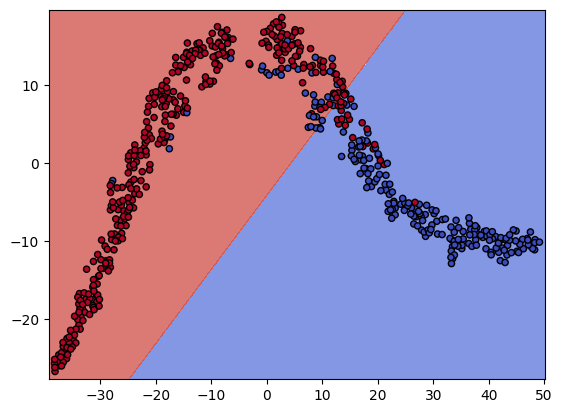
- 거의 대부분 같은 색으로 맞춘 모습
# 교차 검증
estimator = make_pipeline(StandardScaler(), SVC(kernel = 'linear'))
cross_validate(
estimator = estimator,
X = X, y = y,
cv = 5,
n_jobs = multiprocessing.cpu_count(),
verbose = True
)
# 출력 결과
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 2 out of 5 | elapsed: 1.5s remaining: 2.3s
[Parallel(n_jobs=8)]: Done 5 out of 5 | elapsed: 1.5s finished
{'fit_time': array([0.00498796, 0.00498223, 0.00598669, 0.00300407, 0.00298858]),
'score_time': array([0.00199056, 0.00099754, 0.00099754, 0.00091267, 0.00099921]),
'test_score': array([0.96491228, 0.98245614, 0.96491228, 0.96491228, 0.98230088])}# GridSearch
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVC(kernel = 'linear'))])
param_grid = [{'model__gamma': ['scale', 'auto'],
'model__C': [1.0, 0.1, 0.01]}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# C가 0.1일 때 최적
- 해당 예측기로 최종 점수 출력
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.978021978021978
평가 데이터 점수: 1.0
7. 유방암 데이터로 SVC(커널 변경) 실습
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = SVC(kernel = 'rbf')
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.989010989010989
평가 데이터 점수: 0.9385964912280702def make_meshgrid(x, y, h = 0.02):
x_min, x_max = x.min()-1, x.max()+1
y_min, y_max = y.min()-1, y.max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contour(clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = plt.contourf(xx, yy, Z, **params)
return out
X_comp = TSNE(n_components = 2).fit_transform(X)
X0, X1 = X_comp[:, 0], X_comp[:, 1]
xx, yy = make_meshgrid(X0, X1)
model.fit(X_comp, y)
plot_contour(model, xx, yy, cmap = plt.cm.coolwarm, alpha = 0.7)
plt.scatter(X0, X1, c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
- 커널이 linear일 때처럼 선형으로 나눠지지 않고 곡선으로 나눠짐
# 교차 검증
estimator = make_pipeline(StandardScaler(), SVC(kernel = 'rbf'))
cross_validate(
estimator = estimator,
X = X, y = y,
cv = 5,
n_jobs = multiprocessing.cpu_count(),
verbose = True
)
# 출력 결과
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 2 out of 5 | elapsed: 1.6s remaining: 2.5s
[Parallel(n_jobs=8)]: Done 5 out of 5 | elapsed: 1.6s finished
{'fit_time': array([0.0039866 , 0.00697613, 0.00698733, 0.0039866 , 0.00399065]),
'score_time': array([0.00299096, 0.00299168, 0.00397682, 0.00300074, 0.0019927 ]),
'test_score': array([0.97368421, 0.95614035, 1. , 0.96491228, 0.97345133])}# GridSearch
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVC())])
param_grid = [{'model__kernel': ['rbf', 'poly', 'sigmoid']}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_params_
# 출력 결과
{'model__kernel': 'rbf'}
# kernel이 rbf일 때 가장 좋은 성능# kernel은 rbf로 하고 나머지 하이퍼 파라미터 조정
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'rbf'))])
param_grid = [{'model__gamma': ['scale', 'auto'],
'model__C': [1.0, 0.1, 0.01],
'model__epsilon': [1.0, 0.1, 0.01]}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
- 최적 하이퍼 파라미터를 가진 예측기로 최종 점수 출력
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9372487007252107
평가 데이터 점수: 0.8063011852114969'Python > Machine Learning' 카테고리의 다른 글
| [머신러닝 알고리즘] 앙상블 (0) | 2023.02.18 |
|---|---|
| [머신러닝 알고리즘] 결정 트리 (0) | 2023.01.18 |
| [머신러닝 알고리즘] 나이브 베이즈 (0) | 2023.01.10 |
| [머신러닝 알고리즘] K 최근접 이웃 (0) | 2023.01.10 |
| [머신러닝 알고리즘] 로지스틱 회귀 (0) | 2023.01.04 |