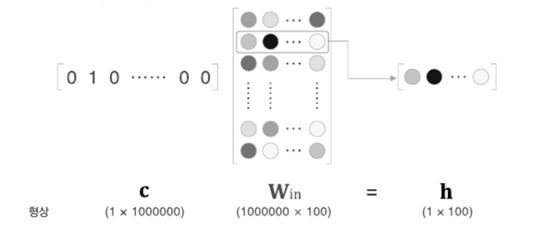
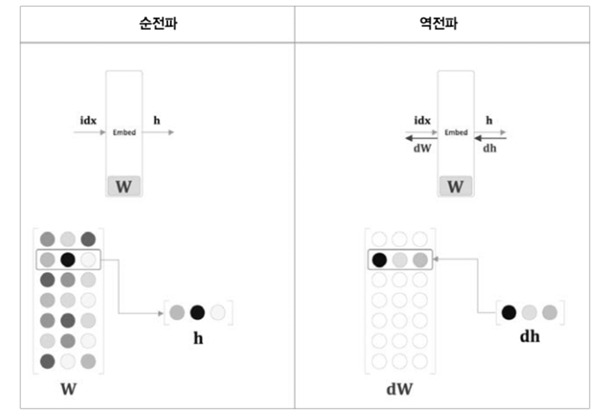
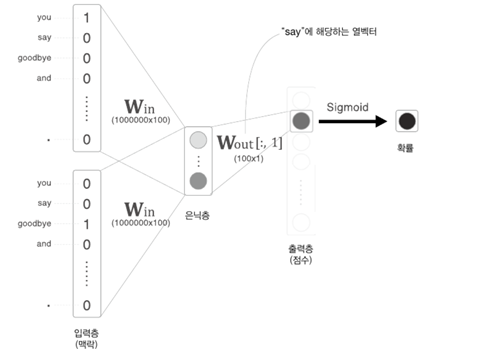
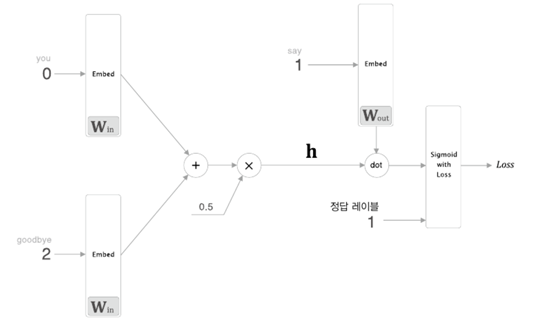
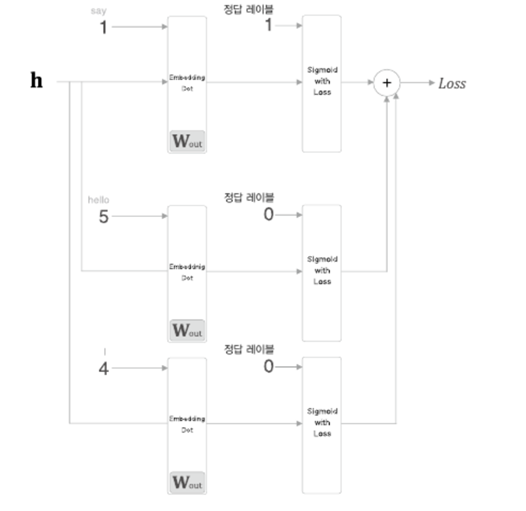
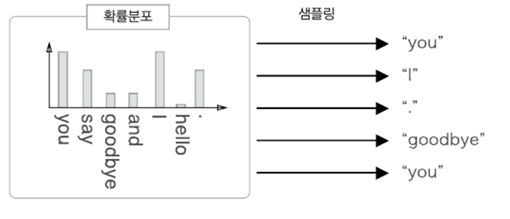
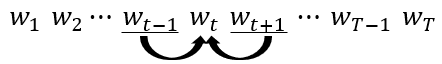1. RNN(Recurrent Neural Network), 순환 신경망
- 특징
- 데이터가 순환하면서 정보가 끊임없이 갱신됨
- 과거의 정보를 기억하는 동시에 최신 데이터로 갱신

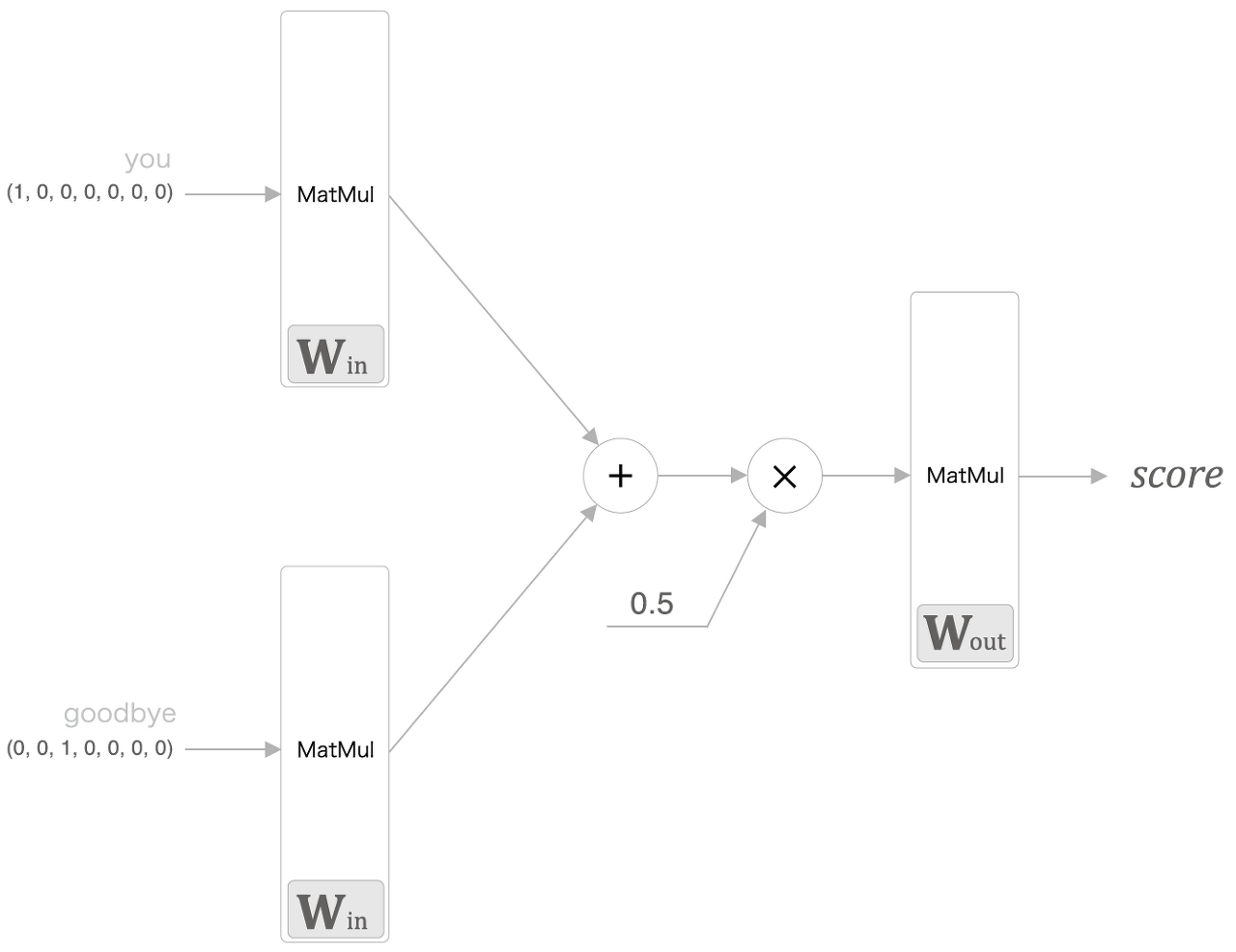
- 수식: \( h_{t}=tanh(h_{t-1}W_{h}+x_{t}W_{x}+b) \)
\( W_{x} \): x를 출력 h로 변환하기 위한 가중치
\( W_{h} \): 1개의 RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치
- BPTT(Back Propagation Through Time)
- 정의: RNN의 오차역전파법

- 긴 시계열 데이터를 학습할 때 문제가 발생
- 과도한 메모리 사용량
- 기울기 값이 조금씩 작아지고, 0이 되어 소멸할 수 있음
- 문제 해결을 위해 Truncated BPTT 사용
- Truncated BPTT
- 기능: 신경망을 적당한 지점에서 잘라내어 작은 신경망 여러 개로 만듦

- 역전파의 연결은 끊어지지만, 순전파의 연결은 끊어지지 않음


- 미니배치 학습
- 미니배치를 나눠서 사용할 때 순서 고려
- 예시) 길이가 1000인 데이터에 대해 시각의 길이를 10개 단위로 잘라서 Truncated BPTT로 학습하는 경우
- 첫번째 미니배치의 원소는 0~9, 두번째 미니배치의 원소는 500~509
- 다음 순서는 10~19, 510~519로, 학습 처리 순서를 고려해서 미니배치의 순서 고려


- Time RNN
- RNN의 연속된 형태를 Time RNN이라는 하나의 형태로 만들어냄

- RNN 순전파


class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
- RNN 역전파

- Time RNN 구현
- 은닉 상태의 h를 인스턴스 변수를 인계받는 용도로 이용

- Time RNN 순전파
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful = False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
# h: 마지막 RNN 계층의 h 저장
# dh: 앞 블록의 기울기 저장
self.h, self.dh = None, None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
# N: 미니배치 크기
# T: T개 분량의 시계열 데이터
# D: 차원수
N, T, D = xs.shape
D, H = Wx.shape
self.layers = []
# hs: 출력값을 담을 그릇(N, T, H만큼의 빈공간을 만들어 둠)
hs = np.empty((N, T, H), stype = 'f')
# 처음 시작 시 초기화
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype = 'f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs- Time RNN 역전파

class TimeRNN:
...
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
# 입력데이터 기울기 정보 저장
dxs = np.empty((N, T, D), dtype = 'f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
# layer.backward(): 입력 데이터 기울기, 이전 h 기울기 반환
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
- RNNLM(RNN Language Model)
- RNN을 사용한 언어 모델

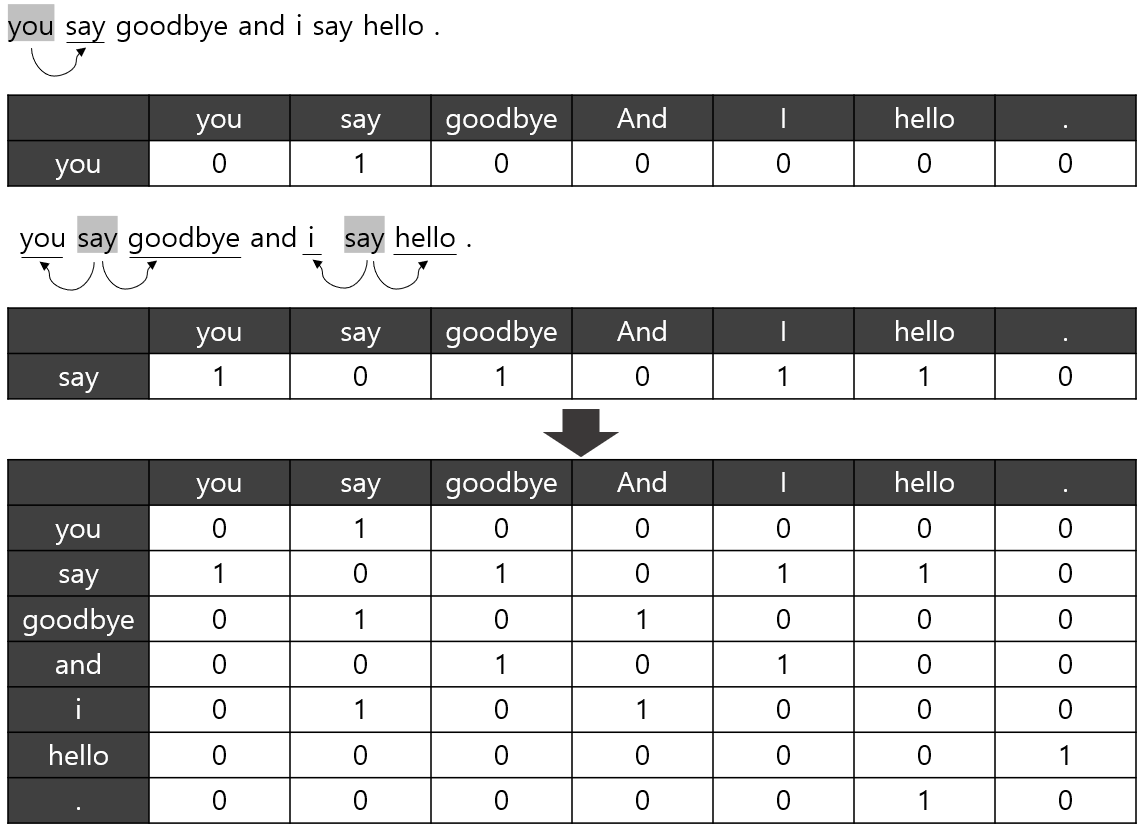
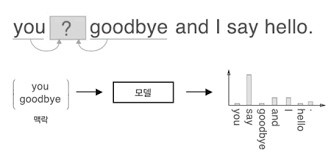
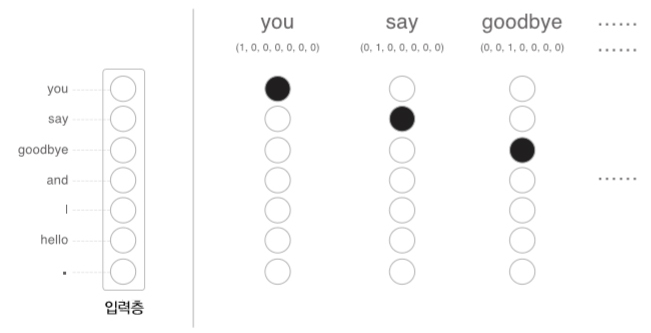
- 샘플 말뭉치('You say goodbye and I say hello.')를 처리하는

- 첫번째 시각
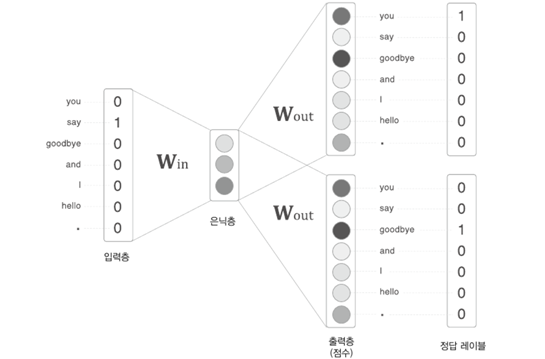
- 첫 단어로 단어 ID가 0인 'you' 입력
- 이때 softmax 계층이 출력하는 확률분포는 'say'가 가장 높음
- 즉, 'you' 다음에 출현하는 단어가 'say'라는 것을 올바르게 예측
- 이처럼 제대로 예측하려면 좋은 가중치(잘 학습된 가중치)를 사용해야 함
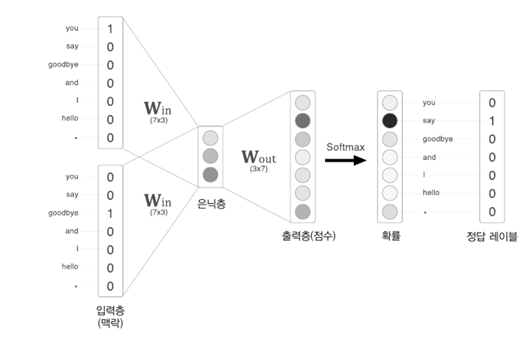
- 두번째 시각
- 두번째 단어로 'say'가 입력
- softmax 계층 출력은 'goodbye'와 'hello'가 높음
- 'you say goodbye'와 'you say hello'는 모두 자연스러움
- 주목할 점
- RNN 계층은 'you say'라는 맥락을 기억하고 있음
- RNN은 'you say'라는 과거의 정보를 응집된 은닉 상태 벡터로 저장해두고 있음
- 그러한 정보를 더 위의 Affine 계층에, 그리고 다음 시각의 RNN 계층에 전달하는 것이 RNN 계층이 하는 일
- Time Affine 계층
- 시간에 따른 변화를 한번에 나타내는 것으로 만들 수 있음
- 각 시각의 Embedding을 합쳐서 Time Embedding으로
- 각 시각의 RNN을 합쳐서 Time RNN으로
- 각 시각의 Affine을 합쳐서 Time Affine으로
- 각 시각의 Softmax을 합쳐서 Time Softmax로

- 시계열 버전의 softmax
- softmax 계층을 구현할 때는 손실 오차를 구하는 Cross Entropy Error 계층도 함께 구현
- 여기서 Time Softmax with Loss 계층으로 구현


- RNNLM 구현
from common.time_layers import TimeEmbedding, TimeAffine
class SimpleRnnlm:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
rnn_Wx = (rn(D, H) / np.sqrt(D)).astype('f')
rnn_Wh = (rn(H, H) / np. sqrt(H)).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful = True),
TimeAffine(affine_W, affine_b)
]
- 퍼플렉서티(Perplexity)
- 기능: 언어 모델의 예측 성능 평가
- 수식: 확률의 역수
- 특징: 작을수록 예측을 잘한 것으로 판별



2. 게이트가 추가된 RNN
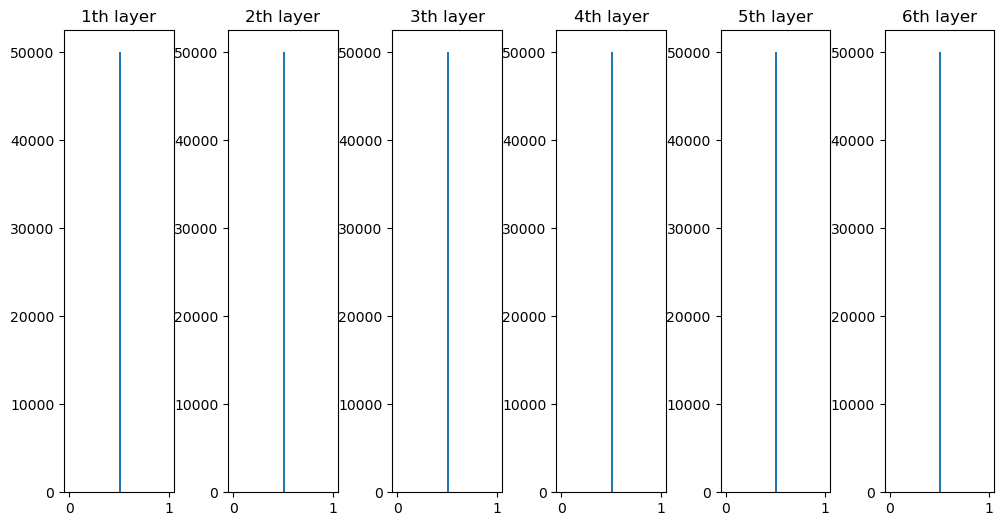
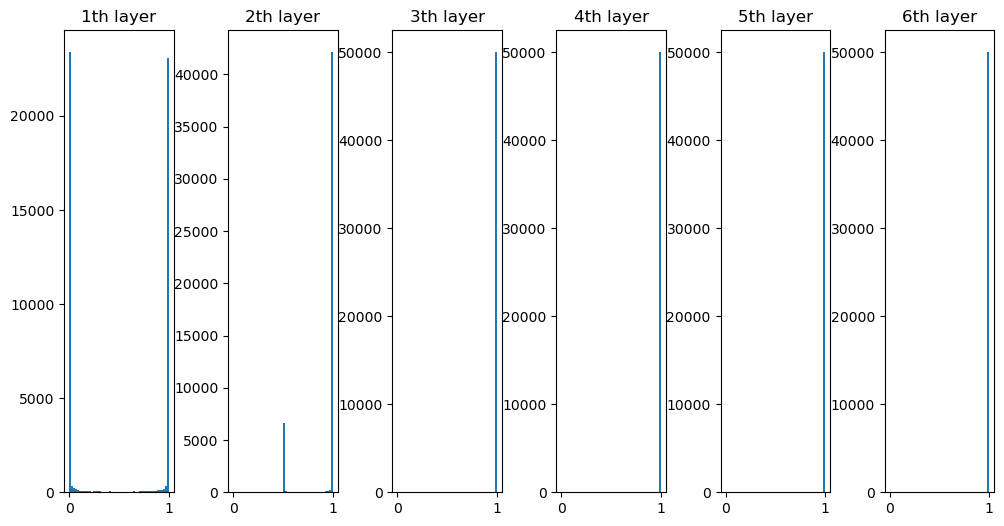
- RNN의 문제점: 길이가 길어지면 기울기가 소실되면 장기 의존 관계를 학습할 수 없음

- 기울기 소실과 기울기 폭발의 원인
- y=tanh(x) 그래프에서 x가 0으로부터 멀어질수록 값이 작아짐


- 매번 똑같은 가중치 \( W_{h} \)를 사용



- 기울기 폭발 대책: clipping
\( if \left || \hat{g} \right || \geq threshold \)
\( \hat{g} = \frac{threshold}{\left || \hat{g} \right ||} \hat{g} \)
import numpy as np
dW1 = np.random.rand(3, 3) * 10
dW2 = np.random.rand(3, 3) * 10
grads = [dW1, dW2]
max_norm = 5.0
def clip_grads(grads, max_norm):
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads:
grad *= rate
print('before:', dW1.flatten())
clip_grads(grads, max_norm)
print('after:', dW1.flatten())
# 출력 결과
before: [0.292 1.409 1.208 5.685 0.065 9.458 2.011 0.732 7.078]
after: [0.069 0.335 0.288 1.353 0.015 2.251 0.479 0.174 1.685]
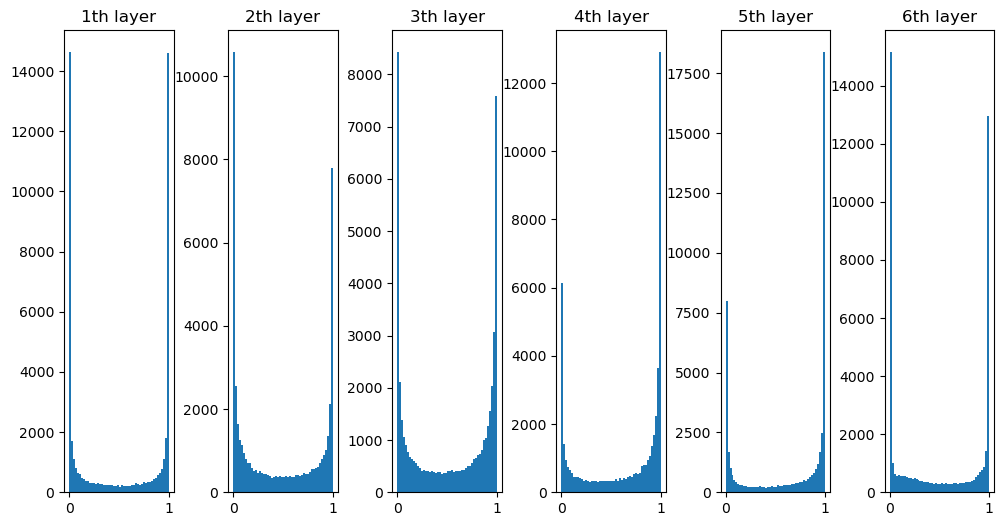
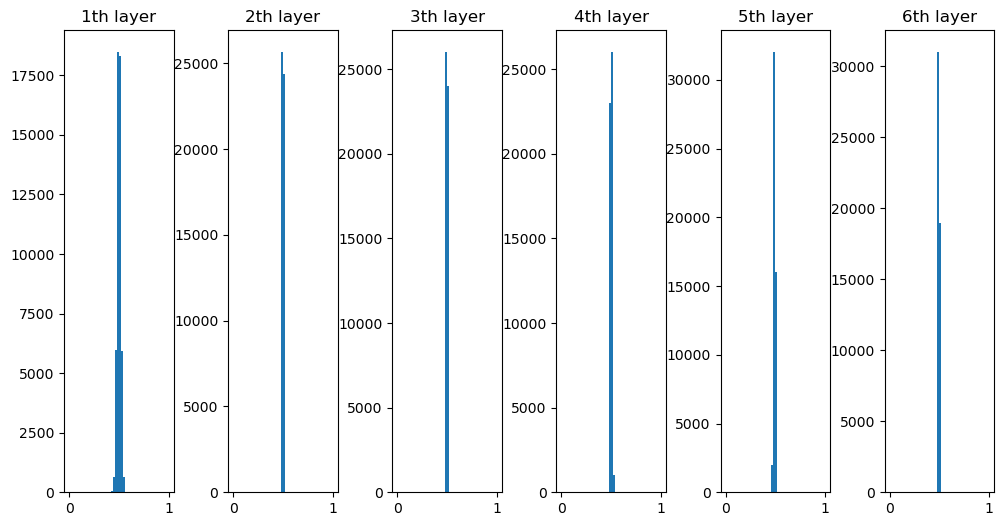
- 기울기 소실과 LSTM
- RNN을 LSTM으로 바꾸면 새로운 c라는 경로가 생김
- c는 메모리셀을 의미, LSTM의 기억을 위한 셀


- LSTM(Long Short Term Memory): 길게 기억할건지, 짧게 기억할건지 흐름을 조절


- LSTM의 output 게이트
- c값을 고려

[1]
입력 \( x_{t} \) 에는 가중치 \( (W_{x})^{(0)} \)가,
이전 시각의 은닉 상태 \( h_{t}-1 \) 에는 가중치 \( (W_{h})^{(0)} \)가 붙어있음 (\( x_{t} \) 와 \( h_{t}-1 \)은 행벡터)
[2]
그리고 이 행렬들의 곱과 편향 \( b^{(o)} \)를 모두 더한 다음
[3]
시그모이드 함수를 거쳐 출력 게이트의 출력 o를 구함.
[4]
마지막으로 이 o와 \( tanh(c_{t}) \)의 원소별 곱을 \( h_{t} \) 로 출력

output 게이트에서 수행하는 계산을‘σ’로 표기
그리고 σ의 출력을 o라고 하면, \( h_{t} \) 는 \( o \)와 \(tanh(c_{t}) \)의 곱으로 계산된다.
- 여기서 말하는 ‘곱’이란 원소별 곱
- 이것을 아다마르 곱 Hadamard product 이라고 함.
- tanh의 출력은 -1.0~1.0의 실수
- 이 -1.0~1.0의 수치를 그 안에 인코딩된 ‘정보’의 강약(정도)을 표시한다고 해석할 수 있음
- 한편 시그모이드 함수의 출력은 0.0~1.0의 실수이며, 데이터를 얼마만큼 통과시킬지를 정하는 비율
- (주로) 게이트에서는 시그모이드 함수가
- 실질적인 ‘정보’를 지니는 데이터에는 tanh 함수가 활성화 함수로 사용됨
- LSTM의 forget 게이트: 불필요한 기억을 잊게 해주는 부분
- LSTM의 새로운 기억 셀(g)



- LSTM 기울기 흐름: 메모리인 c에 어떤 정보가 전달되는지가 중요(잊을 건 잊고, 유지될 건 유지되어 전달되는 형태)

- LSTM 구현
- 수식 구현

- 구현한 수식을 하나로 모으면 아래와 같이 표현 가능(Affine 변환)

from common.functions import sigmoid
class LSTM:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
dc_prev = ds * f
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
dA = np.hstack((df, dg, di, do))
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
- 처음 4개분의 아핀 변환을 한꺼번에 수행
- 그리고 slice 노드를 통해 그 4개의 결과를 꺼냄
- slice: 아핀 변환의 결과(행렬)를 균등하게 네조각으로 나눠서 꺼내주는 단순한 노드
- slice 노드 다음에는 활성화 함수(시그모이드 함수 또는 tanh 함수)를 거쳐 앞 절에서 설명한 계산을 수행
- slice 노드의 역전파: 이 slice 노드는 행렬을 네 조각으로 나눠서 분배
→ 따라서 그 역전파에서는 반대로 4 개의 기울기 결합 필요

- Time LSTM 구현


from common.functions import sigmoid
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful = False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
self.h , self.c = None, None
self.dh = None
self.statful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype = 'f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype = 'f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype = 'f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.appen(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype = 'f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] = grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c = None):
self.h, self.c = h, C
def reset_state(self):
self.h, self.c = None, None
- RNNLM 구현

from common.time_layers import TimeSoftmaxWithLoss
class Rnnlm:
def __init__(self, vocab_size = 10000, wordvec_size = 100, hidden_size = 100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 가중치 초기화
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.rnn_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모음
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss =self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.rnn_layer.reset_state()- 모델 동작 결과 - 장기적으로 기억하고 잊어버릴 건 잊어버리는 게이트 역할을 LSTM이 해줌으로써 더 좋은 성능 출력
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity
# 하이퍼파라미터 설정
batch_size = 20
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 35 # RNN을 펼치는 크기
lr = 20.0
max_epoch = 4
max_grad = 0.25
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_test, _, _ = ptb.load_data('test')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
# 모델 생성
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
# 기울기 클리핑을 적용하여 학습
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad,
eval_interval=20)
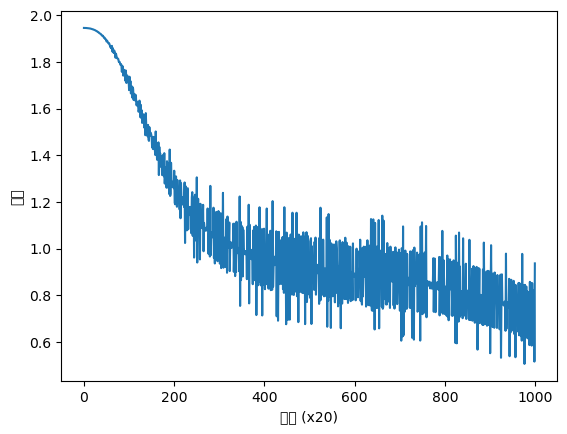
trainer.plot(ylim=(0, 500))
# 테스트 데이터로 평가
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('테스트 퍼플렉서티: ', ppl_test)
# 매개변수 저장
model.save_params()

퍼플렉서티 평가 중 ... 234 / 235 테스트 퍼플렉서티: 135.88121947675342
- RNNLM의 추가 개선: LSTM 계층 다양화
- LSTM 계층을 깊게 쌓아(계층을 여러겹 쌓아) 효과를 볼 수 있음

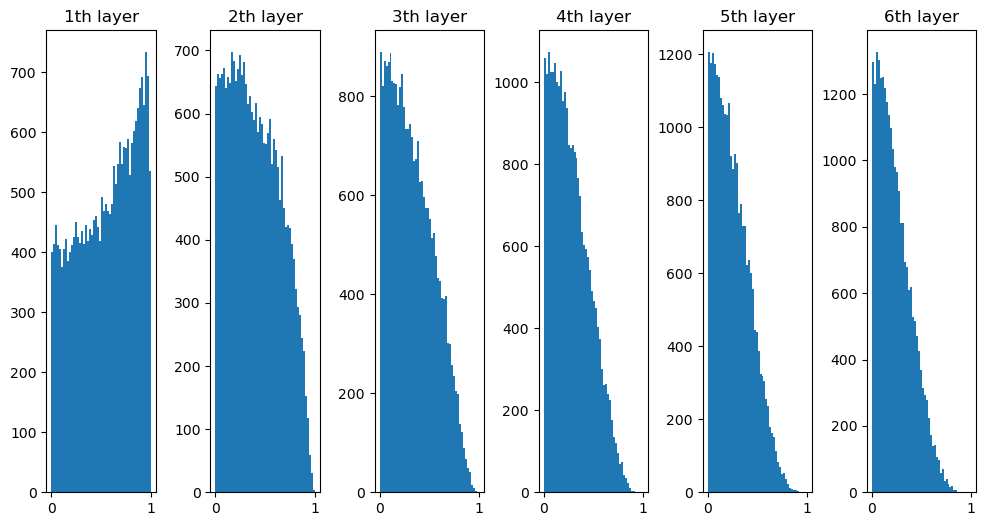
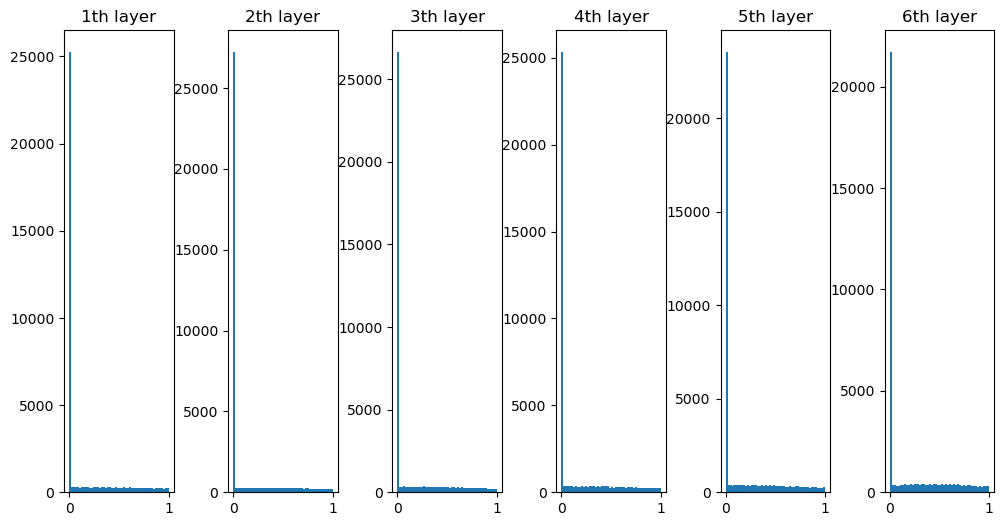
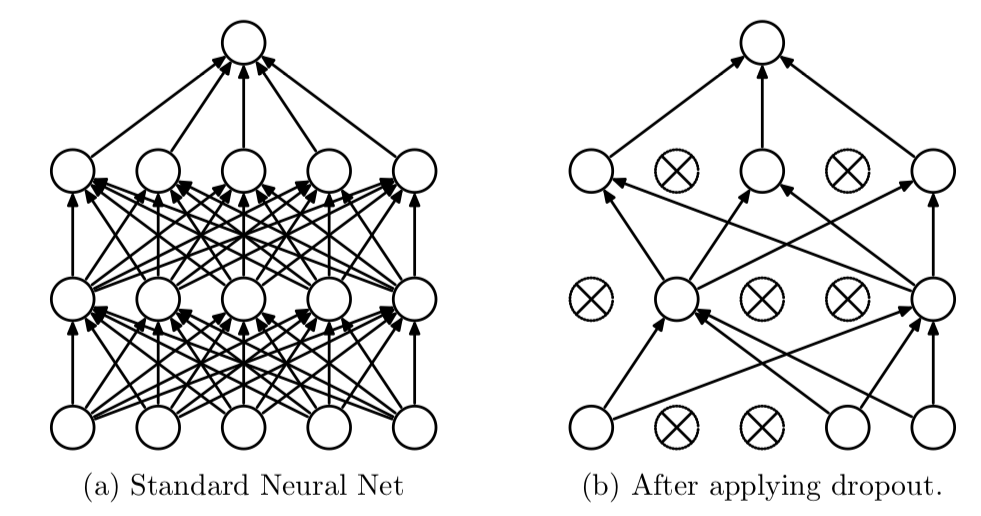
- RNNLM의 추가 개선: 드롭아웃에 의한 과적합 억제
- 망의 일부만 계산에 사용


- 드롭아웃 계층의 삽입 위치(나쁜 예): LSTM 계층의 시계열 방향으로 삽입
- 시계열 방향으로 드롭아웃 학습 시, 흐름에 따라 정보가 사라질 수 있음(흐르는 시간에 비례해 드롭아웃에 의한 노이즈 축적)

- 드롭아웃 계층의 삽입 위치(좋은 예): 드롭아웃 계층을 깊이 방향(상하 방향)으로 삽입
- 시간 방향(좌우 방향)으로 아무리 진행해도 정보를 잃지 않음
- 드롭아웃이 시간축과는 독립적으로 깊이 방향에만 영향을 줌

- 변형 드롭아웃: 깊이 방향은 물론 시간 방향에도 사용가능, 언어 모델의 정확도 향상

- RNNLM의 추가 개선: 가중치 공유
- Embedding의 가중치와 Affine의 가중치를 공유하며
- 매개변수 수가 줄어들고
- 정확도 향상

- 개선된 RNNLM 구현

from common.time_layers import *
import numpy as np
from common.base_model import BaseModel
class BetterRnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# LSTM 계층 2개 사용
# 각 층에 드롭아웃 적용
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
# 가중치 공유
TimeAffine(embed_W.T, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()- 구현된 모델 학습
# 하이퍼파라미터 설정
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 40
max_grad = 0.25
dropout = 0.5
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_val, _, _ = ptb.load_data('val')
corpus_test, _, _ = ptb.load_data('test')
if config.GPU:
corpus = to_gpu(corpus)
corpus_val = to_gpu(corpus_val)
corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('검증 퍼플렉서티: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
# 테스트 데이터로 평가
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('테스트 퍼플렉서티: ', ppl_test)
- 시간은 오래 걸리지만
개선된 모델에서는 퍼플렉서티 감소
'Python > Deep Learning' 카테고리의 다른 글
| [딥러닝-텐서플로우] 텐서플로우 회귀 모델 (0) | 2023.04.26 |
|---|---|
| [딥러닝-텐서플로우] 텐서플로우 기초 (0) | 2023.04.25 |
| [딥러닝 기초] 자연어 처리 (0) | 2023.03.27 |
| [딥러닝 기초] CNN(합성곱 신경망)(2) (0) | 2023.03.23 |
| [딥러닝 기초] CNN(합성곱 신경망)(1) (0) | 2023.03.23 |