데이터 분석에서 중요한 것 중 하나가 데이터 시각화이다. 분석한 결과를 잘 시각화하여 전달하여 다른 사람들도 내가 분석한 데이터에 대해 알게 하는 것이 데이터 분석의 마무리이다. 그렇기에 데이터 시각화를 공부해야겠다고 생각했고, 마침 태블로를 활용한 데이터 시각화를 공부할 수 있는 책을 리뷰할 수 있는 기회가 생겼다. 태블로는 PowerBI와 함께 기업에서 많이 활용하고 있는 데이터 시각화 툴 중 하나로 알고 있다.
리뷰할 책은 이 책이다.
목차는 다음과 같다.
머리말 이 책의 구성과 특징
PART 01 태블로와 함께하는 데이터 시각화 첫걸음 CHAPTER 01 데이터 시각화는 무엇인가요? 01 데이터 시각화의 개념 02 데이터 시각화의 필요성과 역할 03 데이터 시각화의 전략
CHAPTER 02 태블로는 어떤 도구인가요? 04 태블로 제품군에 대한 이해 05 태블로 데스크탑 설치 06 태블로 인터페이스 소개 07 태블로 vs. 엑셀
PART 02 태블로와 함께하는 데이터 시각화, 차트 그리기 CHAPTER 03 데이터 시각화 기본 차트, 무작정 따라 그리기 (1) 08 필드를 시트 위에 올리는 방법 09 데이터 시각화 기본 차트 #1 - 바 차트 10 마크 카드 활용하기 11 데이터 시각화 기본 차트 #2 - 라인 차트 12 라인 차트 vs. 영역 차트 13 데이터 시각화 기본 차트 #3 - 파이 차트 14 파이 차트는 좋은 데이터 시각화 방식이 아니다? 연습 문제
CHAPTER 04 데이터 시각화 기본 차트, 무작정 따라 그리기 (2) 15 상관관계를 시각화하는 차트, 스캐터 플롯 16 추세선 활용하기 17 분포를 시각화하는 차트 #1 - 박스 플롯 18 분포를 시각화하는 차트 #2 - 히스토그램 19 테이블을 직관적으로 표현하는 방식, 하이라이트 테이블 연습 문제
CHAPTER 05 태블로 이해를 위한 열쇠, 핵심 개념 집중 공략 20 태블로 핵심 개념 #1 - 차원과 측정값 21 태블로 핵심 개념 #2 - 연속형과 불연속형 22 태블로 핵심 개념 #3 - Level of Detail 23 태블로의 4가지 계산 방법
CHAPTER 06 데이터 시각화 기본 차트 되짚어 보기
PART 03 태블로와 함께하는 데이터 시각적 분석 CHAPTER 07 시각화 목표를 향한 첫걸음, 데이터 이어 붙이기 24 태블로 데스크탑에서 데이터 결합 작업을? 25 세로로 길쭉하게 결합하는 과정, 유니온 26 가로로 빵빵하게 결합하는 과정 - 조인, 관계, 블렌딩
CHAPTER 08 필터를 활용하여 세부적으로 들여다보기 27 필터에 대한 기본 이해 28 태블로에서 필터는 왜 그렇게 중요한가? 29 추출 데이터의 범위를 조정하는 추출 필터 30 분석 데이터의 범위를 조정하는 데이터 원본 필터 31 데이터 탐색에서 가장 많이 활용되는 차원 필터 32 적용 방식에 따라 다른 의미를 가지는 측정값 필터 33 작동 우선순위를 바꾸는 필터 #1 - 컨텍스트 필터 34 작동 우선순위를 바꾸는 필터 #2 - 테이블 계산 필터와 숨기기 연습 문제
CHAPTER 09 이중 축을 활용하여 비교 맥락 만들기 35 이중 축의 정의, 2개의 축 36 이중 축의 가장 중요한 의미, 비교 맥락 만들기 37 이중 축의 추가적인 활용법, 디자인 요소 더하기 38 이중 축 vs. 결합 축 39 이중 축을 절묘하게 활용하는 도넛 차트 연습 문제
CHAPTER 10 분석 패널을 활용한 데이터 시각화 고도화 40 분석 패널 소개 41 데이터의 의미를 명확히 드러내는 보조선 42 알고리즘을 활용하는 분석 기능 연습 문제
CHAPTER 11 공간적 맥락을 드러내는 지도 시각화 43 태블로와 지도 시각화 44 지도 시각화, 양날의 검 45 지리경계 구역을 표현하는 지도 시각화 46 위치를 정확히 짚어주는 지도 시각화 연습 문제
CHAPTER 12 데이터 시각적 분석 되짚어 보기
PART 04 태블로로 완성하는 정보 종합 상황판, 대시보드 CHAPTER 13 대시보드는 시트의 조합, 그 이상이다 47 대시보드 구성 요소 - 시트, 개체, 동작 48 대시보드 콘텐츠 구성, 육하원칙(5W1H)을 따라가자 49 대시보드 실습을 위한 차트 준비 50 대시보드 인터페이스 51 대시보드 구성 방법 - 바둑판식 vs. 부동 52 시트, 개체, 동작을 활용한 대시보드 구성 53 태블로를 파워포인트처럼 활용하는 스토리
CHAPTER 14 대시보드 되짚어 보기
CHAPTER 15 기본 차트를 넘어 더 넓은 시각화의 영역으로 54 바 차트가 지루할 땐 변형을 생각해보세요 55 날짜 및 시간에 따른 변화를 표현하는 다른 방법들 56 간트 차트의 다양한 활용법
목차에서 알수 있듯이, 엄청 많은 내용을 책에 담고 있다. 책이 두꺼워 보이지 않았는데 넘기다보니 끝없이 많은 내용이 펼쳐졌고 태블로를 활용한 시각화에 대한 거의 모든걸 알 수 있을 것 같은 느낌이었다.
책 내용은 데이터 시각화에 대한 이론과 태블로에 대한 설명으로 시작한다. 이 책의 실습 내용은 태블로 무료 버전을 활용하는 것으로, 누구나 따라하며 공부할 수 있다.
데이터 시각화는 이론 공부가 아니라 직접 해보는 실습이 주요하다고 생각하는데 이런 연습 문제가 챕터마다 있어 직접 배웠던 내용을 따라하고, 응용해볼 수 있어 더 기억에 잘 남고 손에 익어 시각화 방법을 더 잘 활용할 수 있게 될 것 같다.
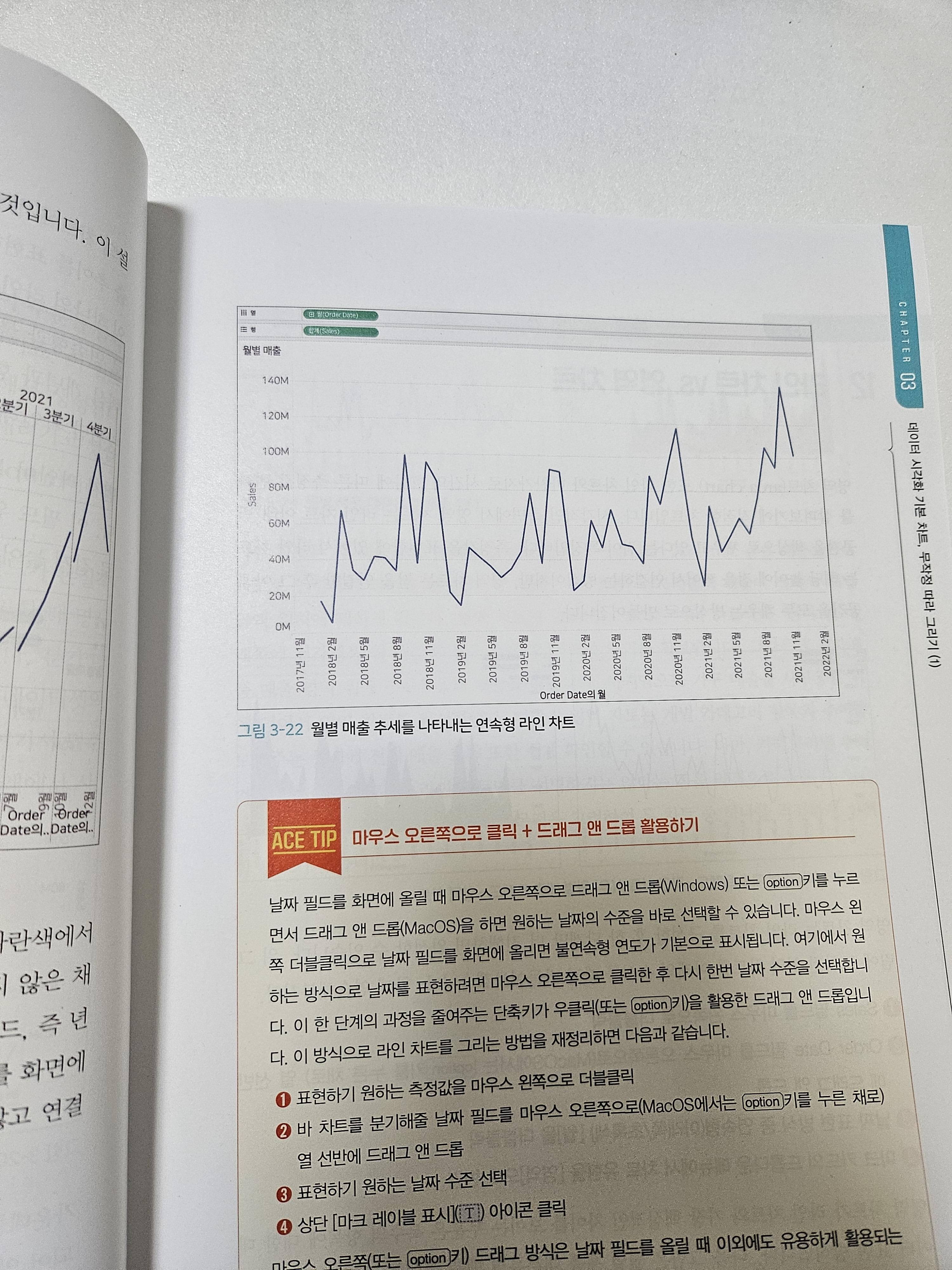
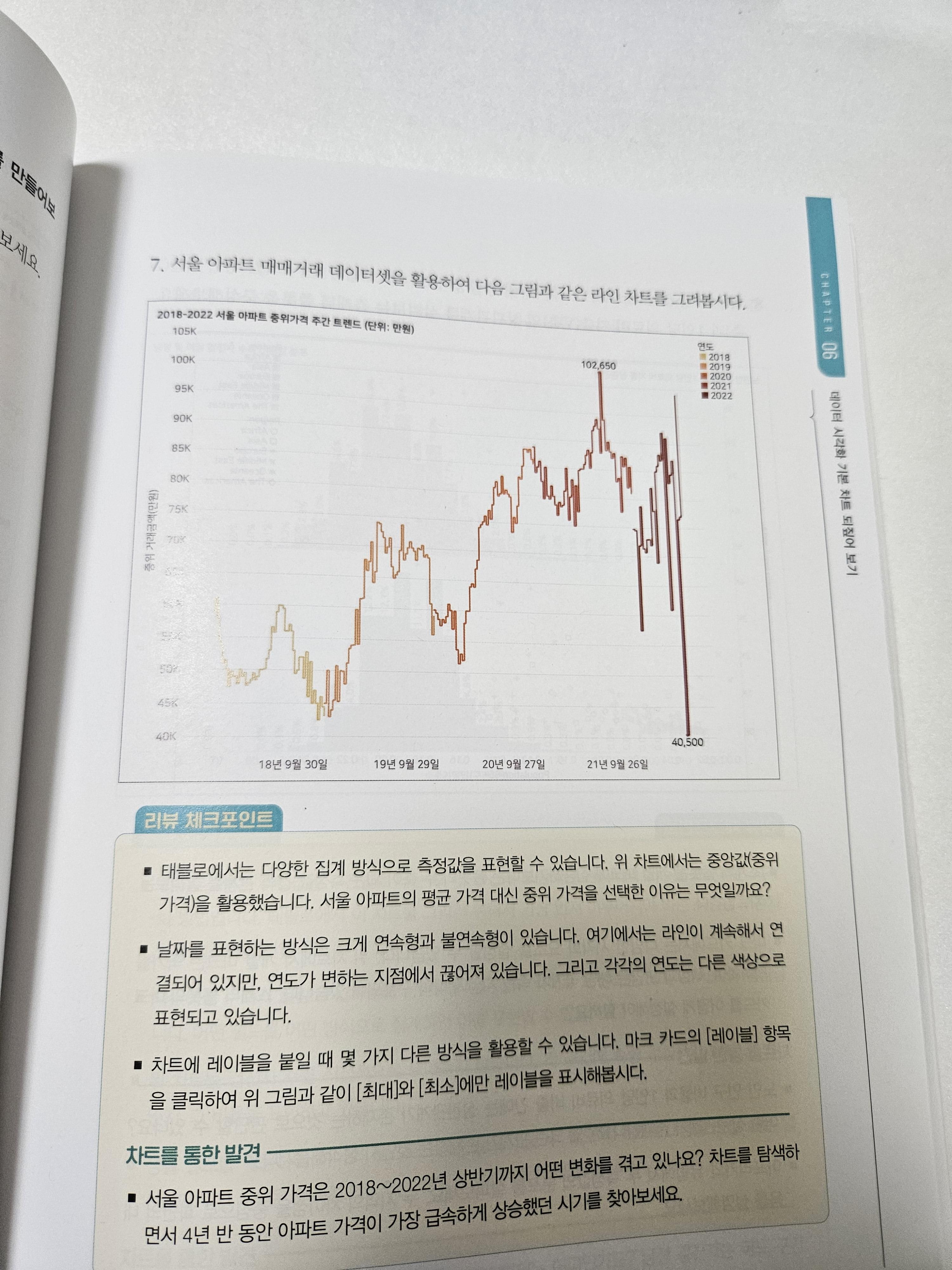
내가 왼쪽의 단순한 라인 차트를 색깔과 요소들을 잘 조합해 오른쪽과 같은 그래프로 만들 수 있게 되다니 믿기지 않았다.
이책으로 공부하면 전체적으로 여러가지 다양한 그래프들을 접해보며 시각화에 대한 감각도 기를 수 있고, 태블로 활용법도 잘 숙지하여 분석 결과를 원하는대로 시각화할 수 있을 것 같다.
파이썬을 사용하여 딥러닝을 구현할 때 사용하는 대표적인 라이브러리로 케라스, 탠서플로우, 파이토치가 있다. 케라스와 탠서플로우를 활용하는 방법은 공부해봤지만 파이토치는 아직 해본 적이 없었다. 맨날 미루고만 있다가 이 책을 발견하여 파이토치를 공부해야겠다는 마음의 불씨가 다시 한 번 피어올랐다.
파이토치를 활용한 딥러닝 모델을 구현하고, 그 모델을 웹 또는 앱으로 개발할 수 있는 라이브러리까지 설명하고 있는 이 책은, 머신러닝과 딥러닝 모델을 구축하고 그 결과를 대시보드로 만들어 관리하고 싶은 나의 목표에 정말 잘 어울리는 책이었다.
목차는 위와 같이 이루어져 있다.
개발 환경에 대해 먼저 설명하고, pyotrch와 함께 딥러닝의 기본 개념에 대한 학습한다. 다음으로, CNN, RNN 등 대표적인 딥러닝 알고리즘을 공부하고 파이토치로 구현까지 같이 해 볼 수 있었다. 마지막으로, Streamlit으로 앱을 개발하고, 앱을 깃허브에 등록하여 배포하는 과정까지 살펴볼 수 있었다.
각 내용에 맞는 코드와 그 코드 실행 결과까지 책에 나와서 실습을 하면서도 내가 맞게 하고 있는 것인지 알기 쉬웠고, 책을 따라가기 쉬웠다.
또한, 구체적인 예제로 공부의 흥미도 더 돋울 수 있었다.
Streamlit은 처음 접해보는 웹 앱 개발 프레임워크였지만, 책의 내용을 따라하며 배우다보니 괜찮은 프레임워크였다. 다음 프로젝트는 Streamlit을 사용하여 구축해봐도 될 것 같다.
● 예시로 '월간 데이콘 쇼츠 - 초전도체 임계온도 예측 AI 헤커톤'의 데이터 사용(train, test, submission 파일 3개 존재)
1. 모듈 임포트
import os
# Seed 고정
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything(42)
# warning 무시
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.tree import DecisionTreeClassifier, DicisionTreeRegressor
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, mean_squared_error, mean_absolute_error, r2_score
2. 데이터 불러오기
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
3. 데이터 탐색
train.head() # 처음 5개의 데이터 (전체적인 데이터 구조 확인)
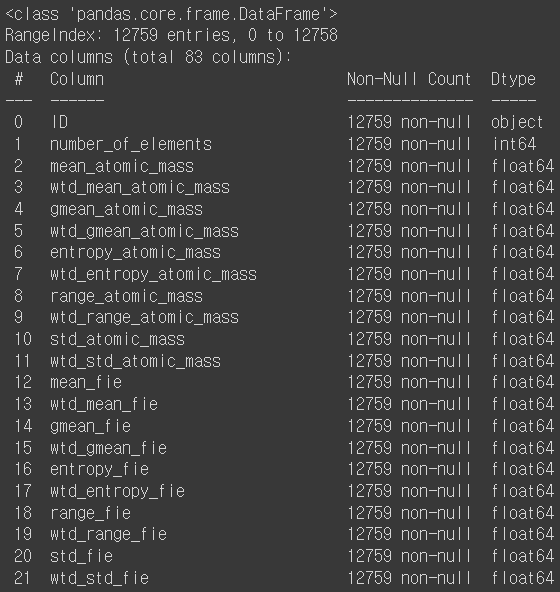
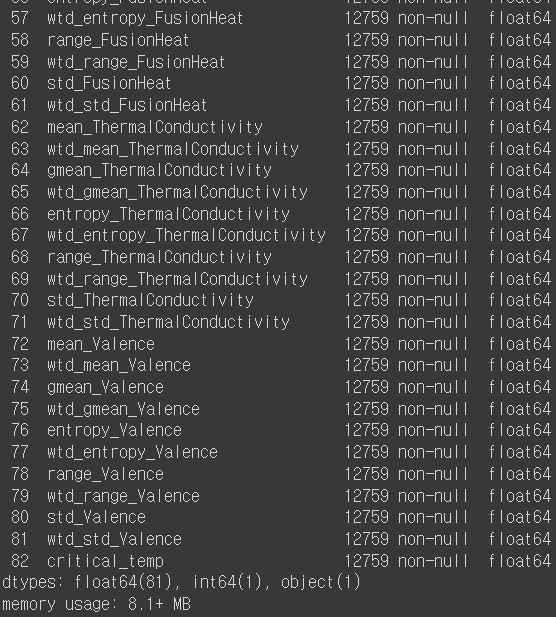
train.info() # 데이터에 대한 개략적인 정보 (행과 열 개수, non-null값 개수, 데이터 타입)
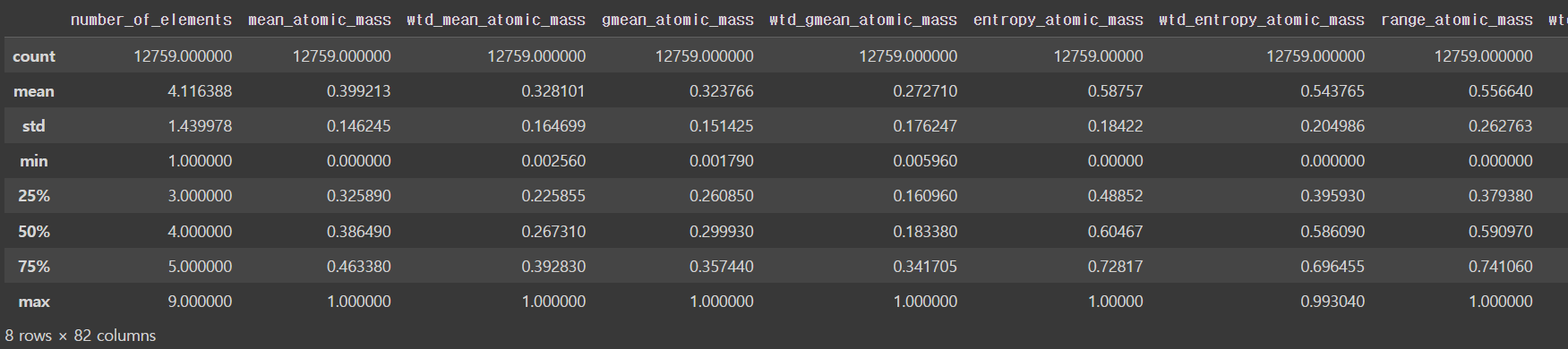
train.describe() # 숫자형 데이터 요약 (개수, 평균, 표준편차, 최소값, 25%, 50%, 75%, 최대값)
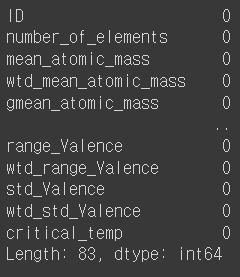
train.isna().sum() # 각 데이터의 결측값 개수
# 이외에도 이해가 가지 않는 행이나 열만 따로 뽑아서 탐색, 데이터 도메인 지식 등을 찾아보며 데이터에 대한 이해 필요
train = train.drop('ID', axis = 1) # train 데이터 탐색 결과 단순 식별자 변수인 ID는 필요 없는 것으로 판단, 삭제
feature = train.copy() # 밑에서 target변수를 제거하고 feature 변수만 남긴 데이터
target = feature.pop('critical_temp') # target 데이터 추출, train에는 feature 데이터만 남음
- train.head(): 처음 5개의 데이터 (전체적인 데이터 구조 확인)
- train.info(): 데이터에 대한 개략적인 정보 (행과 열 개수, non-null값 개수, 데이터 타입)
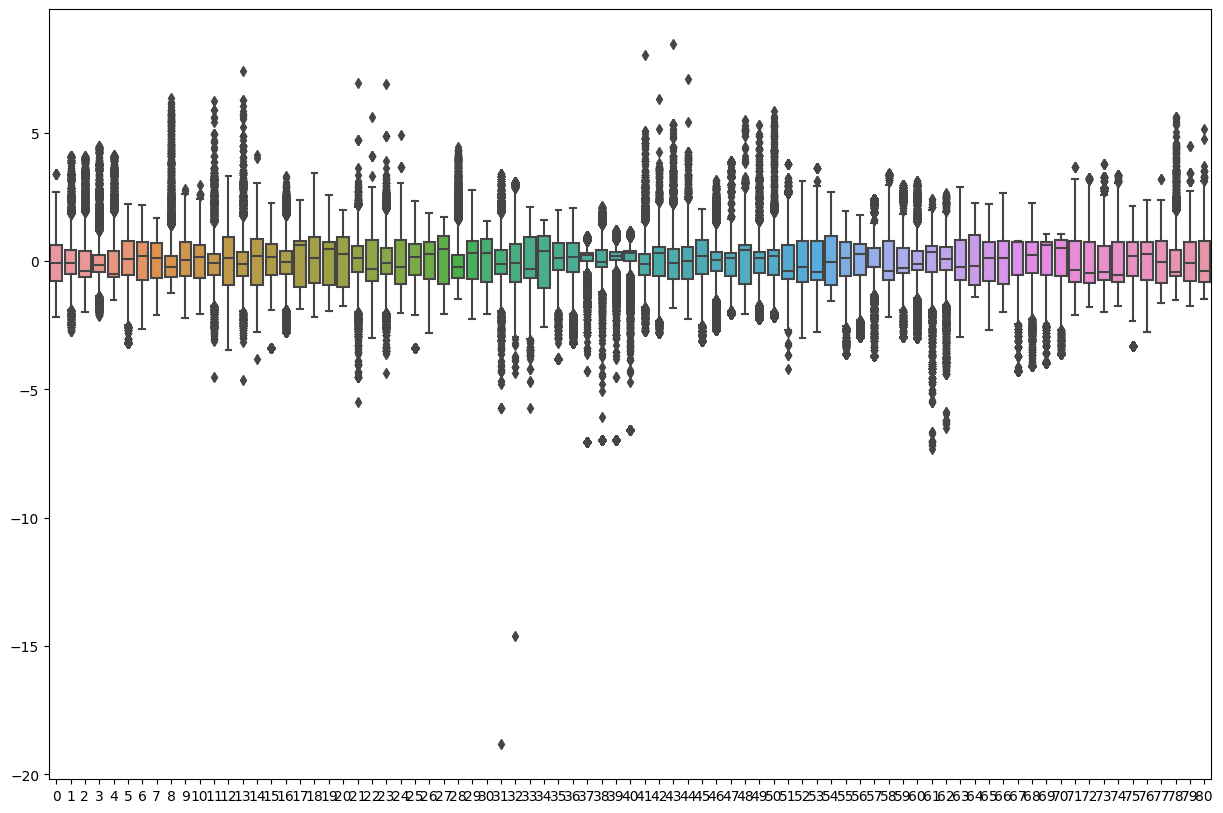
scaler = StandardScaler() # 박스플롯 출력 전 하나의 박스플롯에서 데이터를 한눈에 보기 위해 같은 범위로 임시 스케일링
plt.figure(figsize = (15, 10))
sns.boxplot(scaler.fit_transform(feature))
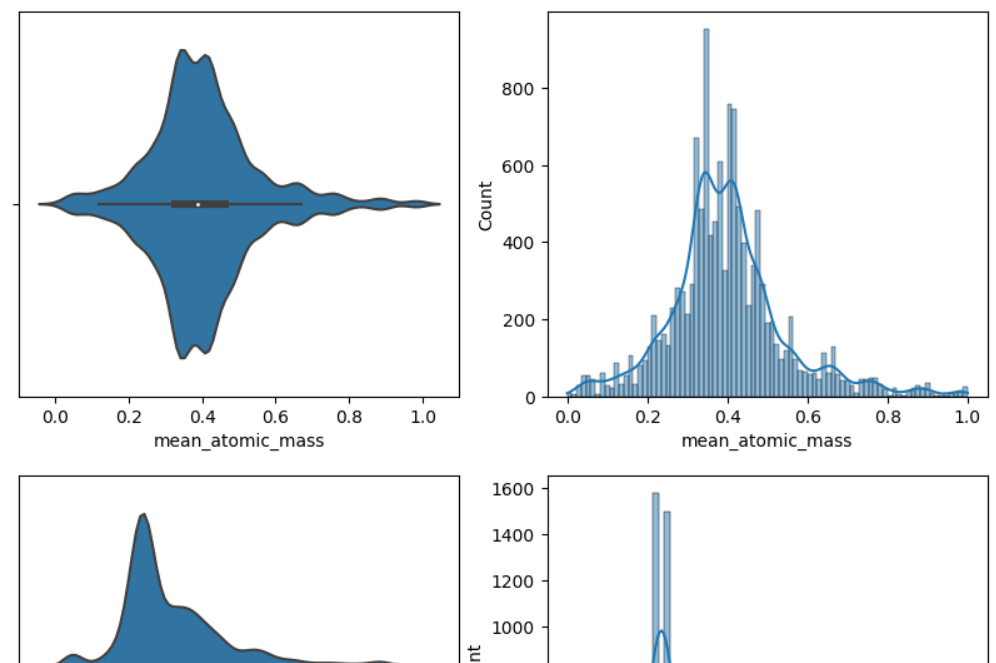
- 각 feature 데이터의 바이오린 플롯과 히스토그램 출력하여 데이터 분포 확인
for col in train.columns:
fig, axs = plt.subplots(nrows = 1, ncols = 2, figsize = (10, 4))
sns.violinplot(x = col, data = train, kde = True, ax = axs[0])
sns.histplot(x = col, data = train, kde = True, ax = axs[1])
# 방법 1. 결측값이 있는 행 제거
feature = feature.dropna(axis = 0, how = 'any') # 각 행에서 하나의 값이라도 NaN이면 해당 행 제거
feature = feature.dropna(axis = 0, how = 'all') # 각 행의 모든 값이 NaN이면 해당 행 제거
# 방법 2. 결측값 채우기(특정 값으로 채우기)
feature = feature.fillna(0) # 0으로 채우기
feature = feature.fillna(method = 'pad') # 바로 앞의 값으로 채우기
feature = feature.fillna(method = 'bfill') # 바로 뒤의 값으로 채우기
feature = feature.fillna(feature.mean()) # 해당 열의 평균값으로 채우기
# 방법 3. 결측값 채우기(보간법)
feature = feature.interpolate(method = 'time') # 인덱스가 날짜/시간일 때 날짜나 시간에 따라 보간
feature = feature.interpolate(method = 'nearest', limit_direction = 'forward') # 가장 가까운 값으로 보간
feature = feature.interpolate(method = 'linear', limit_direction = 'forward') # 양 끝값에 따라 선형식에 적용하여 보간
feature = feature.interpolate(method = 'polynomial', order = 2) # 양 끝값에 따라 다항식에 적용하여 보간 (order은 다항식 차수)
# 방법 4. 결측값이 있는 열을 해당 열의 결측값이 아닌 행과 다른 feature 변수들로 예측하여 채우기
feature_target = feature.pop('결측값 열') # 다른 행들로부터 결측값을 예측할 목표열 분리
target_index = feature_target[feature_target['결측값 열'] == np.nan].index # 목표열 중 결측값인 행의 인덱스 추출
feature_train = feature.iloc[~target_index] # 목표열이 아닌 다른 열에서 결측값이 있는 행의 인덱스가 아닌 행 추축(train 용)
feature_test = feature.iloc[target_index] # 목표열이 아닌 다른 열에서 결측값이 있는 행의 인덱스인 행 추출(test 용)
feature_target_train = feature_target[~target_index] # 목표열 중 결측값이 아닌 행 추출(train 용)
rf = RandomForestRegressor() # 랜덤포레스트로 예측
rf.fit(feature_train, feature_target_train) # 랜덤포레스트에 목표열 중 결측값이 아닌 행을 target 변수, 다른 열의 해당 행들을 feature 변수로 모델 피팅
pred = rf.predict(feature_test) # 피팅된 모델로 목표열에서 결측값인 행 예측
feature.iloc[target_index]['결측값 열'] = pred # 원래 데이터프레임에서 목표열의 결측값인 값을 위에서 예측한 값으로 대체
# 방법 1. 문자형 변수 라벨 인코딩
encoder = LabelEncoder()
feature[[feature.select_dtypes(object).columns]] = encoder.fit_transform(feature.select_dtypes(object))
test[[test.select_dtypes(object).columns]] = encoder.transform(test.select_dtypes(object))
# 방법 2. 문자형 변수 원핫 인코딩
encoder = OneHotEncoder()
feature[[feature.select_dtypes(object).columns]] = encoder.fit_transform(feature.select_dtypes(object).toarray())
test[[test.select_dtypes(object).columns]] = encoder.transform(test.select_dtypes(object).toarray())
- 라벨 인코딩은 문자형 변수 고윳값의 개수에 따라 0부터 n-1까지의 숫자로 변환되어 ML에서 왜곡된 결과를 불러올 수 있음
- 원핫 인코딩은 이런 문제를 해결하기 위해 고윳값의 개수만큼 새로운 feature 변수를 생성하여 각 행에서 고윳값에 해당하는 feature만 1, 나머지는 0으로 표시
9. 모델 피팅 및 예측
# feature 변수와 target 변수 분리
X = feature
y = target
# 학습용 데이터(X_train, y_train)와 검증용 데이터(X_test, y_test)로 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# 모델 선언(사용할 모델로 선정, 예시로는 RandomForestRegressor 선정)
model = RandomForestRegressor()
# 모델 학습
model.fit(X_train, y_train)
# 학습된 모델로 검증용 데이터 예측
y_pred = rf.predict(X_test)
# 실제 검증용 데이터와 예측한 검증용 데이터 비교하여 점수 출력
print(f'mse: {mean_squared_error(y_test, y_pred)}\nmae: {mean_absolute_error(y_test. y_pred)}\naccuracy: {accuracy_score(y_test, y_pred)}')
# 방법 2. cross_val_score
scores = cross_val_score(model, X, y, cv = 5)
for iter, accuracy in enumerate(scores):
print(f'교차 검증 {iter} 정확도: {accuracy:.4f}')
print(f'평균 정확도: {np.mean(scores):.4f}')
- KFold와 cross_val_score에서 각각 평균 정확도가 다른 이유는 cross_val_score가 StratifiedKFold를 이용해 폴드 세트를 분할하기 때문
# 방법 3. GridSearchCV
params = {'max_depth': [2, 3, 5, 10], 'min_samples_split': [2, 3, 5], 'min_samples_leaf': [1, 5, 8]} # 사용할 모델에 맞는 하이퍼 파라미터 중 탐색하고 싶은 범위 지정
grid_model = GridSearchCV(model, param_grid = params, scoring = 'accuracy', cv = 5, verbose = 3) # GridSearchCV에 model, 하이퍼 파라미터, 점수, 교차검증 횟수 등을 파라미터로 지정
grid_model.fit(X_train, y_train) # GridSearchCV 모델에 train 데이터 피팅
print(f'GridSearchCV 최적 하이퍼 파라미터: {grid_model.best_params_}') # 최적 하이퍼 파라미터
print(f'GridSearchCV 최고 정확도: {grid_model.best_score_:.4f}') # 최적 하이퍼 파라미터일 때 나온 최고 점수
best_model = grid_model.best_estimator_ # 최적 하이퍼 파라미터로 최고 점수가 나온 모델을 best_model로 저장
y_pred = best_model.predict(X_test) # best_model로 test 데이터 예측
accuracy = accuracy_score(y_test, y_pred) # 점수 계산
print(f'테스트 세트에서의 model 정확도: {accuracy:.4f}')
11. 기본 분석 이후
- pycaret, autogluon 등 auto ML을 사용해 최적의 모델 선택
- 데이터에 대한 깊은 이해를 통해 더 최적의 변수 선택 및 전처리, 차원 축소 및 군집화 등으로 파생변수 생성
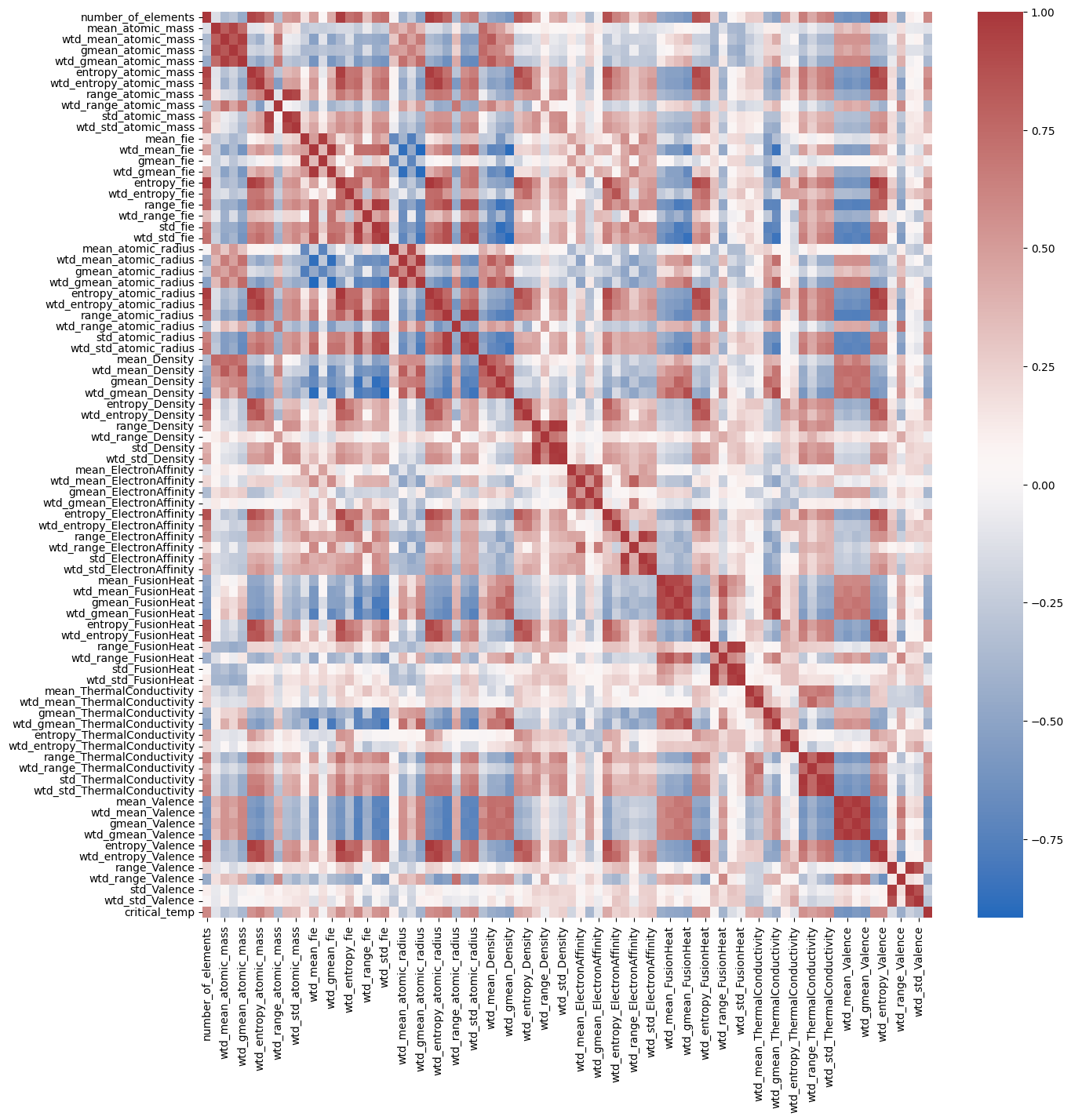
- 지방행정제재·부과금의 징수 등에 관한 법률: 과징금, 이행강제금, 부담금, 변상금, 그 밖의 조세 외의 금전의 체납처분 절차를 규정
- 이 법의 특징은 다른 개별법의 조문에서 '지방행정제재·부과금의 징수 등에 관한 법률을 준용한다'라고 규정하는 경우에 적용
- 현재는 이 법률을 준용하는 개별법을 직접 검색하고 재·개정문을 직접 확인하는 중이라 누락 및 번거로움이 발생
- 국가법령정보센터(현행 법령), 법제처 누리집(입법예고문), 국회 의안정보시스템(의원 발의 법률)의 실시간 관리 자동화 필요
3. 프로젝트 진행 과정
import pandas as pd
import numpy as np
from datetime import datetime
from datetime import timedelta
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import os
from bs4 import BeautifulSoup
import requests
import fitz
from PyQt5 import QtCore, GtGui, QtWidgets
1) 국회 의안정보시스템 크롤링
- 국회 의안정보시스템의 의안 검색 메뉴에서 '지방행정제재·부과금의 징수 등에 관한 법률' 검색
- 검색 결과로 해당 법률을 포함하여 의원이 발의한 의안이 검색됨
- 위 페이지에서 각 의원 발의 법률의 법률명, 제안일, 의결일, 의결 결과를 크롤링하여 정리
# 검색어를 검색한 페이지의 url
# PageSizeOption=100을 변수로 주어 한 페이지에 100개의 게시글까지 나타나도록 설정
url = 'https://likms.assembly.go.kr/bill/BillSearchProposalResult.do?query=지방행정제재ㆍ부과금의+징수+등에+관한+법률&PageSizeOption=100'
# BeautifulSoup를 사용해 해당 url의 html 문서 가져오기
soup = BeautifulSoup(requests.get(url).text, 'html.parser')
# 크롤링하려는 대상인 각 게시글의 제목의 클래스명을 전부 선택하여 추출
result = soup.select('p.ti a')
# 제목에서 추출하려는 대상을 리스트 형식으로 생성
법령명 = []
제안일 = []
의결일 = []
결과 = []
# 각 제목에서 법령명, 제안일, 의결일, 의결 결과를 분리하여 각 리스트에 추가
for i in range(len(result)):
# 법령명은 제목 바로 앞의 'ㆍ'부터 '제안일'이라는 글씨가 나오기 바로 전 까지
법령명.append(str(result[i])[str(result[i]).find('ㆍ') + 1 : str(result[i]).find('제안일')])
# 제안일은 제안일이라는 글씨가 시작되고 6번째부터 '의결일'이라는 글씨가 시작되기 2번째전까지
제안일.append(str(result[i])[str(result[i]).find('제안일') + 6 : str(result[i]).find('의결일') - 2])
# 의결일은 '의결일'이라는 글씨가 시작되고 6번째부터 '의결일'이라는 글씨가 시작되고 12번째까지
의결일.append(str(result[i])[str(result[i]).find('의결일') + 6 : str(result[i]).find('의결일') + 16])
# 결과는 '의결일'이라는 글씨가 시작되고 18번째부터 마지막에서 5번째전까지
결과.append(str(result[i])[str(result[i]).find('의결일') + 18 : -5])
# 각 리스트에 추가해둔 전체 데이터를 데이터프레임으로 결합
의안 = pd.DataFrame({'법령명' : 법령명, '제안일' : 제안일, '의결일' : 의결일, '결과' : 결과})
# 제안일과 의결일을 날짜 형식으로 바꾸지 위해 '.'로 연월일이 나눠져 있던 것을 '-'로 나뉘도록 변경
의안[['제안일', '의결일']] = 의안[['제안일', '의결일']].replace('.', '-')
# 제안일과 의결일을 datetime 형식으로 변경
의안['제안일'] = 의안['제안일'].apply(lambda x: pd.to_datetime(x))
# 의결일 중 의결이 아직 되지 않은 것은 </a>로 되어 있고 이는 '미정'이라는 글자로 변경
의안['의결일'] = 의안['의결일'].apply(lambda x: pd.to_datetime(x) if x != ' </a>' else '미정')
# 제안일과 의결일을 다시 str 형식으로 변경
# datetime 형식으로 두면 00:00:00이라는 시간까지 포함되어 출력되므로 str 형식으로 깔끔하게 정리
의안 = 의안.astype({'제안일':'str', '의결일':'str'})
# 의결일은 '미정'이라는 글씨를 따로 처리('미정'은 그대로 '미정', 미정이 아니면 str로 바꾼 뒤 마지막에서 9번째 자리 글자까지 추출)
의안['의결일'] = 의안['의결일'].apply(lambda x: str(x)[:-9] if x != '미정' else '미정')
# 결과도 결과가 나오지 않았다면 빈 셀로 남아있으므로 이 빈 셀을 '미정'으로 변경
의안['결과'] = 의안['결과'].apply(lambda x: '미정' if x == '' else x)
# 정리한 데이터프레임을 엑셀 파일로 저장
의안.to_excel('의안목록.xlsx', index = False)
2) 법제처 누리집 크롤링
- 법제처 누리집에서 법이 입법되기 전 예고하는 입법예고문 크롤링
- 입법예고문은 pdf 형식으로 올라가 있으므로 pdf 형식의 입법예고문을 최신순으로 일정 개수 다운 받고 텍스트를 추출하여 '지방행정제재·부과금의 징수 등에 관한 법률'이라는 텍스트가 있는지 여부를 검색
- 입법예고문에 키워드가 있다면 해당 입법예고문의 제목을, 그렇지 않으면 '해당없음'을 출력
# 다운받은 입법예고문을 저장할 폴더 생성 후 경로 지정
# '입법예고문'이라는 이름의 폴더가 없다면 새로 생성
if not os.path.exists("입법예고문"):
os.mkdir("입법예고문")
# '입법예고문'폴더로 경로 지정
os.chdir("입법예고문")
# 1페이지부터 4페이지까지 크롤링
for i in range(1, 5):
# '입법예고문' 폴더 내에 각 페이지 마다 '입법예고문_1page', '입법예고문_2page' 등 폴더 생성
if not os.path.exists(f"입법예고문_{i}page"):
os.mkdir(f"입법예고문_{i}page")
# 경로는 새로 만든 폴더로 이동
os.chdir(f"입법예고문_{i}page")
# url의 currentPage 변수에 페이지 번호를 전달하여 각 페이지를 불러오도록 함
# pageCnt 변수를 10 이상의 수로 조정해도 됨
url = f'https://www.moleg.go.kr/lawinfo/makingList.mo?mid=a10104010000¤tPage={i}&pageCnt=10&keyField=&keyWord=&stYdFmt=&edYdFmt=&lsClsCd=&cptOfiOrgCd='
# 위 url의 html 문서 불러오기
soup = BeautifulSoup(requests.get(url).text, 'html.parser')
# 입법예고문의 pdf 파일 다운로드 버튼을 눌러 다운받는 방식
# pdf 파일 다운로드 버튼이 첫번째인 경우도 있고 두번째인 경우, 그 외 경우 등이 있어 예외처리
try:
# html 문서에서 클래스명이 'wrap title' div를 찾기(각 페이지의 게시글 url)
for href in soup.find_all('div', 'wrap title'):
# 각 게시글 url을 지정하여 html 문서 불러오기
page_url = "https://www.moleg.go.kr" + href.find('a')['href'].replace("¤", '¤')
page_soup = BeautifulSoup(requests.get(page_url).text, 'html.parser')
# 문서 다운로드 버튼을 찾아 버튼의 이름을 탐색
title = page_soup.find('div', 'tb_contents').find('ul').find('a').text
# 버튼 이름에 pdf가 포함되어 있으면 pdf 파일임을 확인하고 클릭
if 'pdf' in title:
title = page_soup.find('div', 'tb_contents').find('ul').find('a').text[:title.find('pdf') + 3]
file_url = page_soup.find('div', 'tb_contents').find('ul').find('a')['href']
# 해당 버튼을 눌러 pdf 다운로드 페이지로 이동(이동하면 자동 다운로드 됨)
file = requests.get(file_url)
# PyMuPDF 라이브러리를 사용하여 pdf파일의 텍스트 추출
with open(title, 'wb') as f:
f.write(file.content)
pdf = fitz.open(title)
cnt = 0
# pdf의 각 페이지에서 키워드를 검색
# 없으면 -1, 있으면 개수가 출력됨
for page in pdf:
text = page.get_text()
result = text.find('지방행정제재ㆍ부과금의 징수 등에 관한 법률')
# 모든 페이지에 키워드가 없어 모든 결과가 -1이라면 각 결과를 -한 결과는
# pdf의 모든 페이지 개수와 동일할 것
cnt -= result
# 모든 페이지에 키워드가 없어 모든 결과가 -1이라면 각 결과를 -한 결과는
# pdf의 모든 페이지 개수와 동일할 것
# 따라서 둘을 비교하여 각 pdf에 키워드가 있는지 확인
# 키워드가 없으면 '해당없음'
# 키워드가 있으면 입법예고문 pdf의 제목 출력
if cnt == len(pdf):
print('해당없음')
# 키워드가 없으면 pdf를 삭제하는 코드이지만 오류 해결 못함
# os.unlink(os.getcwd() + title)
else:
print(title + '에서 "지방행정제재ㆍ부과금의 징수 등에 관한 법률"이 개정됨')
# pdf 파일의 다운로드 버튼 위치가 두번째인 경우 html 문서에서 찾을 버튼을 두번째 버튼으로 변경
# 이하 동일
elif 'pdf' in page_soup.find('div', 'tb_contents').find('ul').find_all('a')[1].text:
title = page_soup.find('div', 'tb_contents').find('ul').find_all('a')[1].text
title = page_soup.find('div', 'tb_contents').find('ul').find_all('a')[1].text[:title.find('pdf') + 3]
print(title)
file_url = page_soup.find('div', 'tb_contents').find('ul').find_all('a')[1]['href']
file = requests.get(file_url)
with open(title, 'wb') as f:
f.write(file.content)
pdf = fitz.open(title)
for page in pdf:
text = page.get_text()
result = text.find('지방행정제재ㆍ부과금의 징수 등에 관한 법률')
cnt -= result
if cnt == len(pdf):
print("해당없음")
self.molegText.append("해당없음")
# os.unlink(os.path(os.getcwd() + title))
else:
print(title + '에서 "지방행정제재ㆍ부과금의 징수 등에 관한 법률"이 개정됨')
self.molegText.append(title + '에서 "지방행정제재ㆍ부과금의 징수 등에 관한 법률"이 개정됨')
self.law_count += 1
# 버튼의 위치 이외에 pdf 파일이 존재하지 않는 등의 경우에는 생략하는 것으로 예외 처리
else:
continue
# 버튼의 위치 이외에 pdf 파일이 존재하지 않는 등의 경우에는 생략하는 것으로 예외 처리
except:
pass
# 한 페이지를 끝낸 뒤 다시 상위 폴더인 '입법예고문' 폴더로 경로 지정
os.chdir('..')
# 모든 페이지의 입법예고문을 다운받은 후에는 입법예고문의 상위 경로(입법예고문 크롤링 이전 원래의 경로)로 이동
os.chdir('..')
3) 국가법령정보센터 크롤링
- 국가법령정보센터에는 현행 법령 및 입법예고가 된 시행 예정법령의 모든 조문 검색 가능
- 법령의 조문에'지방행정제재·부과금의 징수 등에 관한 법률'이 있는 것을 검색하여 크롤링
- 크롤링하려는 법령 데이터가 html 문서 내에서 나타나는 것이 아닌 서버에서 실시간으로 받아오는 것으로 BeautifulSoup로 크롤링 불가능
- 페이지 내에 csv 파일을 다운 받을 수 있는 버튼이 있어 이 버튼을 눌러 csv 파일을 받는 것으로 동적 크롤링
# chromedriver 옵션 설정
chrome_options = webdriver.ChromeOptions()
# chromedriver를 직접 열지 않고 내부적으로 실행시키는 옵션
chrome_options.add_argument('--headless')
# chromedriver에서 다운받은 파일의 경로 지정하는 옵션(현재 경로로 지정)
chrome_options.add_experimental_option('prefs', {'download.default_directory':r'{}'.format(os.getcwd())})
# chromedriver 실행
driver = webdriver.Chrome(options = chrome_options)
# 국가법령정보센터로 접속(검색어 '지방행정제재·부과금의 징수 등에 관한 법률' 적용)
driver.get('https://www.law.go.kr/lsSc.do?menuId=1&subMenuId=15&tabMenuId=81&eventGubun=060114&query=지방행정제재·부과금의+징수+등에+관한+법률')
# 상세검색 클릭
driver.find_element(By.XPATH, r'//*[@id="dtlSch"]/a[1]').click()
# 법률 체크 클릭
driver.find_element(By.XPATH, r'//*[@id="AA1"]').click()
# 검색 클릭
driver.find_element(By.XPATH, r'//*[@id="detailLawCtDiv"]/div[3]/div[2]/a').click()
# 검색 결과 불러오는 동안 대기
time.sleep(1)
# 파일 저장 버튼 클릭
driver.find_element(By.XPATH, r'//*[@id="WideListDIV"]/div[1]/div[1]/div[3]/div[13]/button').click()
# 파일 저장형식 xls로 클릭
driver.find_element(By.XPATH, r'//*[@id="saveForm"]/div[1]/div/div[2]/a[1]').click()
# Alert 창 뜨는 동안 대기
time.sleep(1)
# Alert 창 확인 클릭
result = driver.switch_to.alert
result.accept()
# 다운 받아지는 동안 대기
time.sleep(1)
# chromedriver 종료
driver.quit()
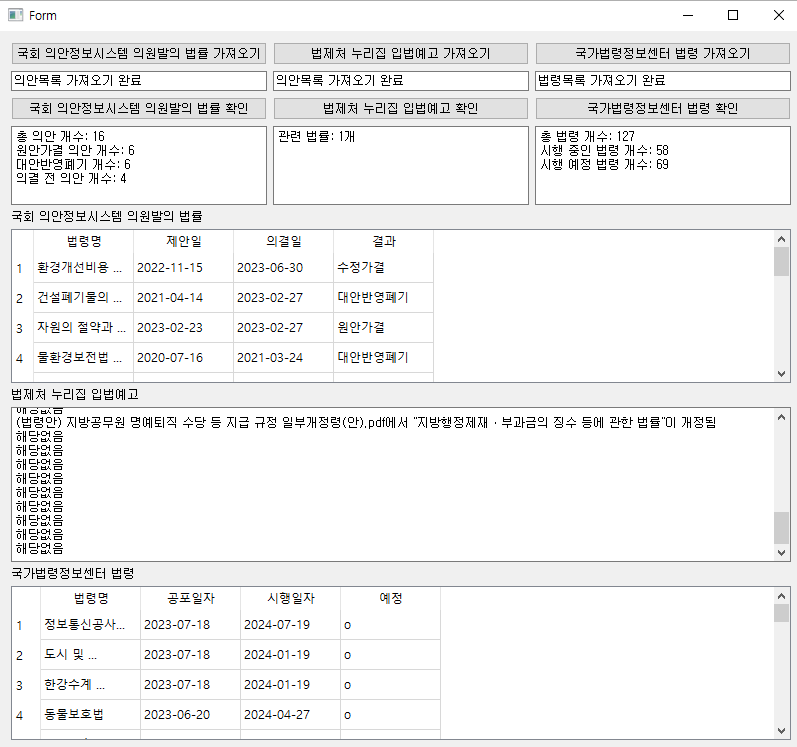
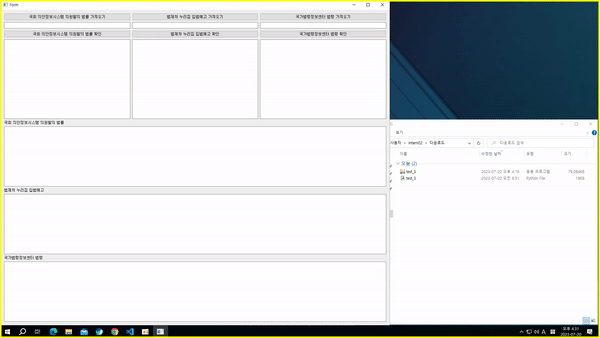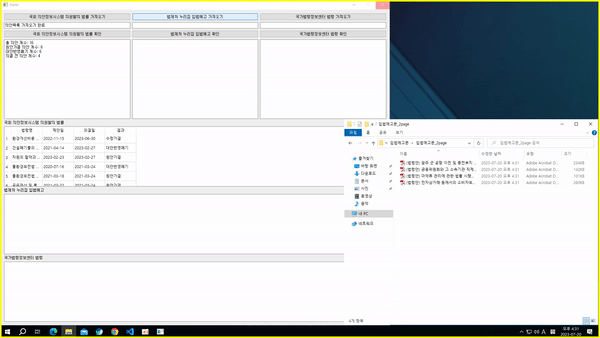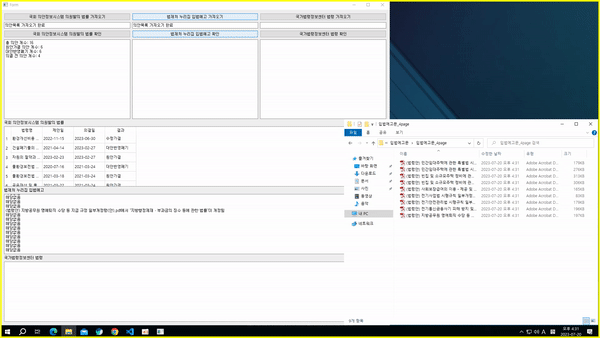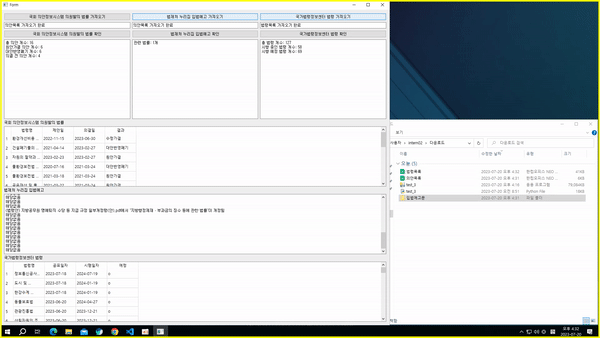
4) 크롤링 과정 통합하여 프로그램화
- pyqt5 사용
- 기본 틀 만들기
- 법안의 발의 과정에 따라 의원발의 법안 → 입법예고문 → 현행 법령 순서로 크롤링 기능 배치
조건을 넣어 True인 값만 출력하도록 하면 조건에 맞지 않는 값은 삭제된 것과 같은 상태
import pandas as pd
df = pd.read_csv('titanic.csv')
# 데이터프레임에서 Sex열의 값이 male이 아닌 것 즉, female인 것만 출력, male은 삭제되고 female인 것만 출력됨
df[df['Sex'] != 'male'].head(2)
# 행의 인덱스를 사용해 하나의 행을 삭제할 수 있음
# 인덱스가 0인 행만 제외하고 나머지 출력
df[df.index != 0].head(2)
12. 중복된 행 삭제하기
drop_duplicates 사용(매개변수 사용에 주의)
# drop_duplicates를 매개변수 없이 사용하면 완벽하게 같은 행만 삭제되어 예시로 사용하는 타이타닉 데이터에서는 삭제되는 열이 없음
print('원본 데이터프레임 행의 수: {}'.format(len(df)))
print('drop_duplicates 사용한 데이터프레임 행의 수: {}'.format(len(df.drop_duplicates())))
# 출력 결과
원본 데이터프레임 행의 수: 891
drop_duplicates 사용한 데이터프레임 행의 수: 891
# 따라서 중복을 비교할 열을 subset 매개변수에 전달하여야 함
# Sex 변수에서 중복되는 값이 전부 제거되고 제일 처음 male값을 가지는 행과 female 값을 가지는 행만 남아 출력됨
df.drop_duplicates(subset = ['Sex'])
# keep 매개변수에 last를 전달하면 가장 마지막에 남은 male값과 female값만 하나씩 출력됨
df.drop_duplicates(subset = ['Sex'], keep = 'last')
13. 값에 따라 행을 그룹핑하기
groupby('그루핑할 열')['통계 계산을 할 열'].통계계산(mean, sum, count 등)
# 성별로 그루핑하여 각 성별의 나이 평균 계산
df.groupby('Sex')['Age'].mean()
# 출력 결과
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64
첫 번째 열로 그루핑한 다음 두 번째 열로 다시 그룹핑하기
# 성별로 구루핑 하고 각 성별 중 생존 여부에 따라 다시 그루핑
# 이후 총 4개의 그룹 각각의 나이 평균 계산
df.groupby(['Sex', 'Survived'])['Age'].mean()
# 출력 결과
Sex Survived
female 0 25.046875
1 28.847716
male 0 31.618056
1 27.276022
Name: Age, dtype: float64
14. 시간에 따라 행을 그루핑하기
시간을 인덱스로 하는 예시 데이터프레임 생성
import pandas as pd
import numpy as np
# 2023/06/26부터 30초 간격으로 100,000개의 시간 데이터를 인덱스로 생성
time_index = pd.date_range('06/26/2023', periods = 100000, freq = '30s')
# 위에서 생성한 시간 인덱스를 인덱스로하고, 1~10사이의 숫자 중 랜덤하게 100,000개를 뽑은 것을 각 시간의 값으로 생성
df = pd.DataFrame(index = time_index)
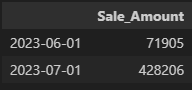
df['Sale_Amount'] = np.random.randint(1, 10, 100000)
df
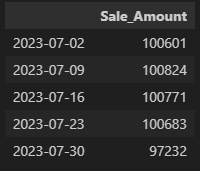
# 일주일 단위로 행을 그루핑
df.resample('W').sum()
시간 단위
'W': 1주 단위
'2W': 2주 단위
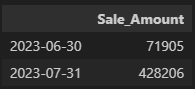
'M': 1달 단위
'MS': 1달 단위, 그루핑된 인덱스를 월의 시작 날짜로
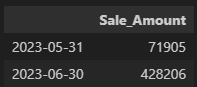
label = 'left' 옵션: 인덱스를 그루핑된 그룹의 마지막 레이블이 아닌 그 전 그룹의 마지막 레이블로 변환
# 데이터프레임의 ['Name']열에 속한 값들을 하나씩 차례대로 name으로 지정하여 출력(상위 2개의 열에만 예시로 적용)
for name in df['Name'][0:2]:
print(name.upper())
16. 모든 열 원소에 함수 적용하기
데이터프레임의 특정 열의 모든 값에 동시에 함수를 적용
# 문자를 대문자로 출력하는 함수 생성
def uppercase(x):
return x.upper()
# 위에서 생성한 함수를 데이터프레임의 'Name'열에 한번에 적용(상위 2개의 열에만 예시로 적용)
df['Name'].apply(uppercase)[0:2]
map 함수도 apply 함수와 비슷하지만 map 메서드는 딕셔너리를 입력으로 넣을 수 있고 apply 메서드는 매개변수를 지정할 수 있음
# 딕셔너리 형태로 Survived 열의 1값은 Live, 0값은 Dead로 변경
df['Survived'].map({1 : 'Live', 0 : 'Dead'})[:5]
apply 메서드에서 age라는 매개변수 전달
# age = 30이라는 매개변수 전달, Age열의 값이 전달받은 age보다 작은지에 대한 boolean 값 return
df['Age'].apply(lambda x, age: x < age, age = 30)[:5]
applymap 메서드로 전체 데이터프레임에 함수 적용 가능
# 문자값으로 이루어진 열에 대해 최대 길이를 20자로 제한하는 함수
def truncate_string(x):
if type(x) == str:
return x[:20]
else:
return x
전체 데이터프레임에 적용
df.applymap(truncate_string)[:5]
17. 그룹에 함수 적용하기
# Sex열로 그루핑하여 male 그룹과 female 그룹의 다른 열들 각각에 lambda 함수 적용
df.groupby('Sex').apply(lambda x: x.count())
# 방법 2(numpy 배열을 dataframe으로)
import numpy as np
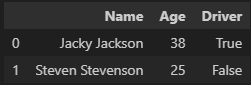
data = [['Jacky Jackson', 38, True], ['Steven Stevencon', 25, False]]
matrix = np.array(data)
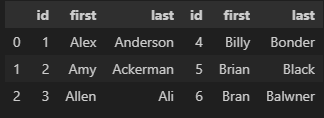
pd.DataFrame(matrix, columns = ['Name', 'Age', 'Driver'])
# or
pd.DataFrame(data, columns = ['Name', 'Age', 'Driver'])
# 방법 3(dictionary를 dataframe으로)
data = {'Name': ['Jacky Jackson', 'Steven Stevenson'],
'Age': [38, 25],
'Driver': [True, False]}
pd.DataFrame(data)
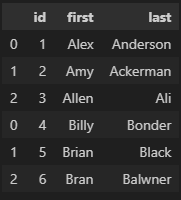
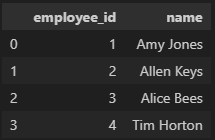
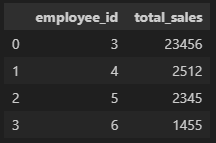
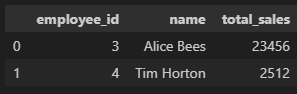
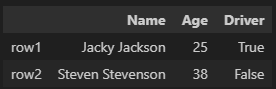
# 방법 4(각각의 데이터를 dictionary로, 각 dictionary를 병합)
data = [{'Name': 'Jacky Jackson', 'Age': 25, 'Driver': True},
{'Name': 'Steven Stevenson', 'Age': 38, 'Driver': False}]
# 인덱스 따로 지정 가능
pd.DataFrame(data, index = ['row1', 'row2'])
2. 데이터 설명하기
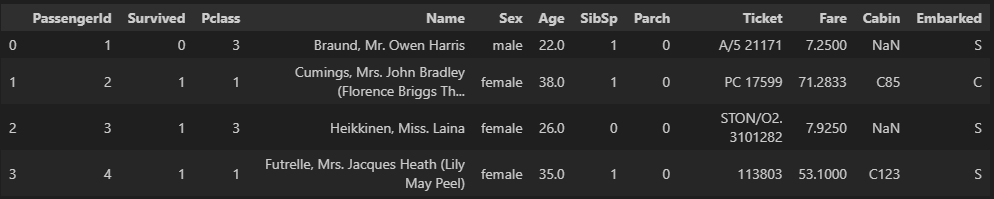
데이터를 적재한 후 확인하는 가장 간단한 방법은 head()를 통해 상위 몇 개의 데이터만 출력해서 확인해보는 것
tail()을 사용하면 하위 데이터 출력
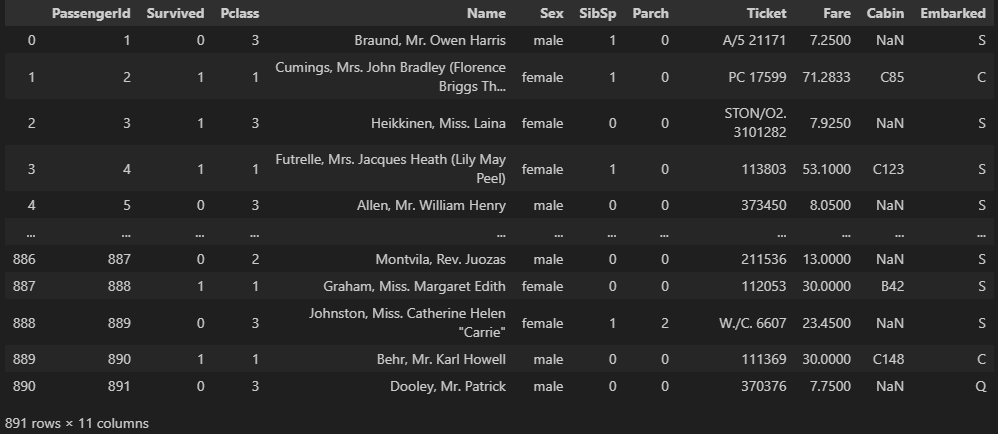
df = pd.read_csv('titanic.csv')
# 데이터의 상위 2행만 출력
df.head(2)
데이터의 열과 행의 개수 확인
df.shape
# 출력 결과
(891, 12)
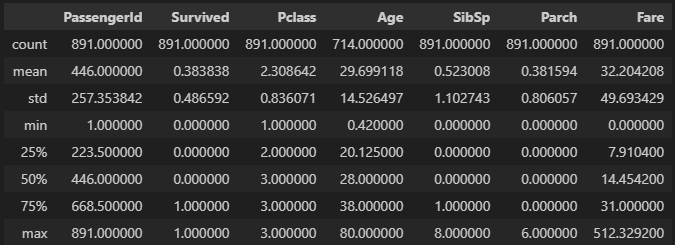
describe()를 사용하여 숫자데이터 열의 통계값 확인
df.describe()
3. 데이터프레임 탐색하기
loc 또는 iloc를 사용해 하나 이상의 행이나 값을 선택
loc와 iloc 슬라이싱은 numpy와 달리 마지막 인덱스를 포함
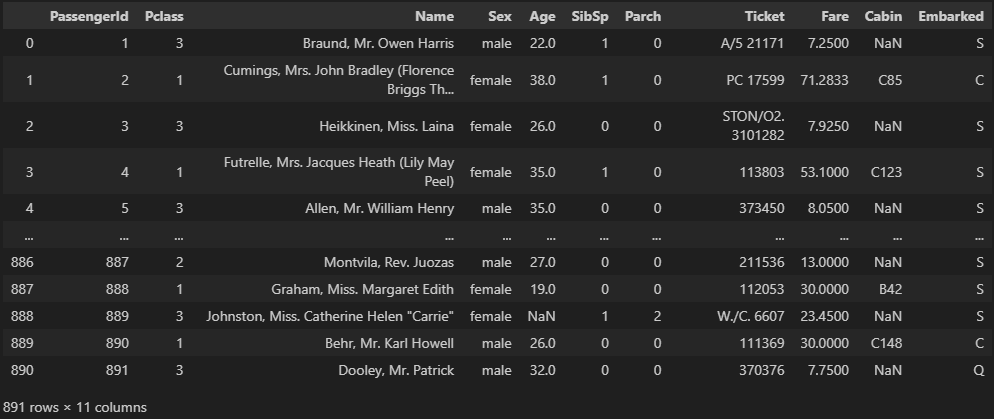
# 첫번째 행 출력
df.iloc[0]
# 출력 결과
PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
Sex male
Age 22.0
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Cabin NaN
Embarked S
Name: 0, dtype: object
# 콜론(:)을 사용하여 행 슬라이싱
# 첫번째 행부터 네번째 행까지 출력
df.iloc[1:4]
# 슬라이싱의 첫 부분을 공백으로 두면 처음부터 선택
# 슬라이싱의 마지막 부분을 공백으로 두면 마지막까지 선택
df.iloc[:4]
# 데이터프레임에서 행마다 고유한 값을 갖는 특정 열을 인덱스로 설정
# loc를 사용해 고유값으로 해당 행을 슬라이싱 가능
df_name_index = df.set_index(df['Name'])
df_name_index.loc['Braund, Mr. Owen Harris']
# 출력 결과
PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
Sex male
Age 22.0
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Cabin NaN
Embarked S
Name: Braund, Mr. Owen Harris, dtype: object
# 열을 선택하여 선택한 열만 출력하기도 가능
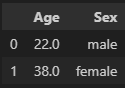
df[['Age', 'Sex']].head(2)
4. 조건에 따라 행 선택하기
# 데이터프레임 df[] 안에 조건문인 df['Sex'] == female을 넣어서 True인 행만 출력
df[df['Sex'] == 'female'].head(2)
# &를 사용해 조건 두 개이상도 검색 가능
df[(df['Sex'] == 'female') & (df['Age'] >= 60)].head(2)
5. 값 치환하기
df['Sex'].replace('female', 'woman').head(2)
# 출력 결과
0 male
1 woman
Name: Sex, dtype: object
# 두 개 이상도 한번에 치환 가능
df['Sex'].replace(['female', 'male'], ['woman', 'man']).head(5)
# 출력 결과
0 man
1 woman
2 woman
3 woman
4 man
Name: Sex, dtype: object
# 한번에 여러 값은 하나의 값으로 치환 가능
df['Sex'].replace(['female', 'male'], 'person').head(5)
# 출력 결과
0 person
1 person
2 person
3 person
4 person
Name: Sex, dtype: object
# 치환할 여러 값을 딕셔너리 형태로 전달 가능
df['Sex'].replace({'female' : 1, 'male' : 0}).head(5)
# 출력 결과
0 0
1 1
2 1
3 1
4 0
Name: Sex, dtype: int64
# 위에서 하나의 열뿐 아니라 데이터프레임 전체의 모든 값을 한번에 치환 가능
df.replace(1, 'one').head(2)
df.count()
# 출력 결과
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64
8. 고유값 찾기
unique 메서드를 사용해 열에서 고유한 값을 모두 찾음
df['Sex'].unique()
# 출력 결과
array(['male', 'female'], dtype=object)
nunique 메서드는 unique 값의 개수를 출력
df['Sex'].nunique()
# 출력 결과
2
# nunique는 데이터프레임 전체에 적용 가능
df.nunique()
# 출력 결과
PassengerId 891
Survived 2
Pclass 3
Name 891
Sex 2
Age 88
SibSp 7
Parch 7
Ticket 681
Fare 248
Cabin 147
Embarked 3
dtype: int64
value_counts() 메서드를 사용해 열에서 고유한 값 각각의 개수 출력
df['Sex'].value_counts()
# 출력 결과
Sex
male 577
female 314
Name: count, dtype: int64
9. 누락된 값 다루기
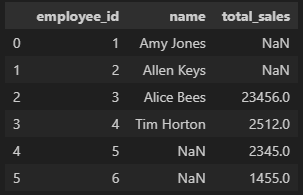
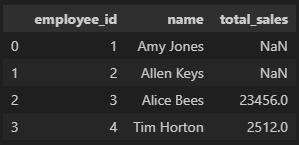
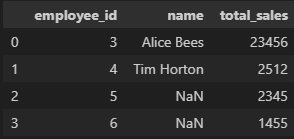
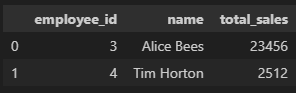
isnull()과 notnull() 메서드는 null인지 아닌지에 대한 답을 boolean값(True나 False)으로 나타냄
# 조건으로 isnull()을 주어 True나 False의 값이 나오므로 True인 행만 찾아 출력 가능
df[df['Age'].isnull()].head()
read_csv() 메서드에서 na_values = [] 옵션을 사용해 null 값으로 선언할 값들은 지정
read_csv() 메서드에서 keep_default_na 옵션을 False로 하여 pandas에서 기본적으로 null 값으로 인식하는 값을을 null값이 아니게 만들 수 있음
read_csv() 메서드에서 na_filter 옵션을 False로 하면 NaN 변환을 하지 않음
10. 열 삭제하기
drop() 메서드 사용
# 축은 열을 나타내는 1로 지정
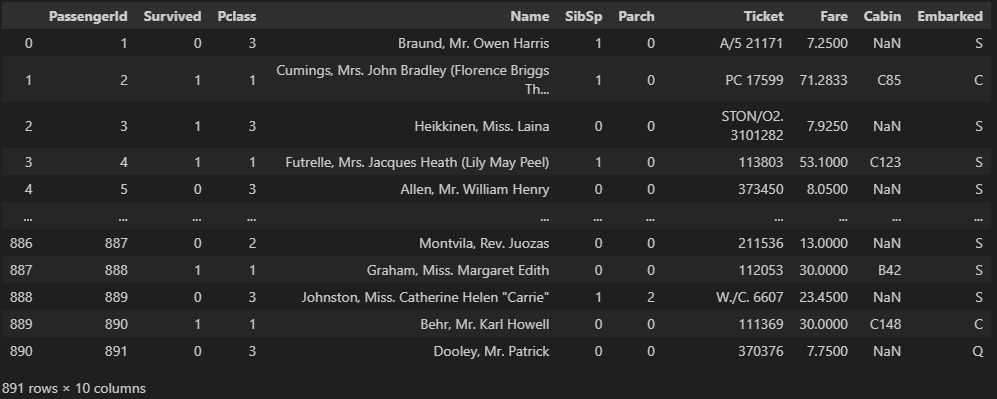
df.drop('Age', axis = 1)
한 번에 여러개의 열 삭제 가능
df.drop(['Age', 'Sex'], axis = 1)
열 이름이 없다면 열의 인덱스 번호를 사용해 삭제 가능
# 인덱스가 1인 열(두번째 열) 삭제
df.drop(df.columns[1], axis = 1)
del df['Age']를 사용해 열을 삭제할 수 있지만 이는 원보 데이터프레임을 바꿔 원본 데이터의 손상을 유발할 수 있어 추천 X
digits.keys()
# 출력 결과
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])
# DESCR 키는 데이터셋에 대한 설명
print(digits['DESCR'])
# 출력 결과
.. _digits_dataset:
Optical recognition of handwritten digits dataset
--------------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 1797
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
...
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
load_데이터셋의 유일한 매개변수인 return_X_y를 True로 하면 특성 X와 타깃 y배열을 반환
import numpy as np
# digits 함수는 특별히 n_class 매개변수를 사용하여 필요한 숫자 개수 지정가능
# 0~4까지 5개의 숫자만 y값에 넣도록 매개변수 설정
X, y = datasets.load_digits(n_class = 5, return_X_y = True)
np.unique(y)
# 출력 결과
array([0, 1, 2, 3, 4])
2. 모의 데이터셋 만들기
선형 회귀 알고리즘에 사용하려면 make_regression 추천
make_regression은 실수 특성 행렬과 실수 타깃 벡터 반환
from sklearn.datasets import make_regression
# n_features는 전체 특성
# n_informative는 타깃 벡터 생성에 사용할 특성
features, target, coefiicients = make_regression(n_samples = 100,
n_features = 3,
n_informative = 3,
n_targets = 1,
noise = 0.0,
coef = True,
random_state = 1)
from sklearn.datasets import make_regression
features, target, coefiicients = make_regression(n_samples = 100,
n_features = 3,
n_informative = 3,
n_targets = 1,
noise = 0.0,
coef = True,
random_state = 1)
print('특성 행렬\n', features[:3])
print('타깃 벡터\n', target[:3])
# 출력 결과
특성 행렬
[[ 1.29322588 -0.61736206 -0.11044703]
[-2.793085 0.36633201 1.93752881]
[ 0.80186103 -0.18656977 0.0465673 ]]
타깃 벡터
[-10.37865986 25.5124503 19.67705609]
분류 알고리즘에 사용하려면 make_classification 추천
make_classification은 실수 특성 행렬과 정수 타깃 벡터 반환
from sklearn.datasets import make_classification
# n_redundant는 필요없는 특성의 수, n_informative 특성의 랜덤 선형 결합으로 생성됨
# weights는 차례대로 각각 첫번째 ,두번째 클래스의 비율
features, target = make_classification(n_samples = 100,
n_features = 3,
n_informative = 3,
n_redundant = 0,
n_classes = 2,
weights = [.25, .75],
random_state = 1)
print('특성 행렬\n', features[:3])
print('타깃 벡터\n', target[:3])
# 출력 결과
특성 행렬
[[ 1.06354768 -1.42632219 1.02163151]
[ 0.23156977 1.49535261 0.33251578]
[ 0.15972951 0.83533515 -0.40869554]]
타깃 벡터
[1 0 0]
군집 알고리즘에 사용하려면 make_blobs 추천
make_blobs은 실수 특성 행렬과 정수 타깃 벡터 반환
from sklearn.datasets import make_blobs
features, target = make_blobs(n_samples = 100,
n_features = 2,
centers = 3,
cluster_std = 0.5,
shuffle = True,
random_state = 1)
print('특성 행렬\n', features[:3])
print('타깃 벡터\n', target[:3])
# 출력 결과
특성 행렬
[[ -1.22685609 3.25572052]
[ -9.57463218 -4.38310652]
[-10.71976941 -4.20558148]]
타깃 벡터
[0 1 1]
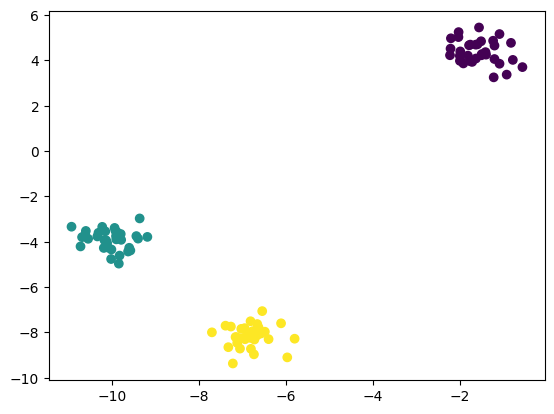
# 만들어진 군집 데이터 시각화
# pip install matplotlib
import matplotlib.pyplot as plt
plt.scatter(features[:, 0], features[:, 1], c = target)
plt.show()
3. CSV 파일 적재하기
pandas 라이브러리의 read_csv() 사용
매개변수
sep = ',': 파일이 사용하는 구분자를 ','로 지정
skiprows = range(1, 11): 1행부터 12행까지 건너뛴 후 출력
nrows = 1: 한 행 출력
import pandas as pd
dataframe = pd.read_csv('csv 경로')
4. 엑셀 파일 적재하기
pandas 라이브러리의 read_excel() 사용
read_excel()을 사용하려면 xlrd 패키지 설치 필요
매개변수
sheet_name: 시트 이름 문자열 또는 시트의 위치를 나타내는 정수(0부터 시작되는 인덱스)
na_filter: 결측값 탐지, 결측값이 없는 데이터라면 해당 옵션을 제외하는 것이 성능 향상에 도움
먼저, SQLite 데이터베이스 엔진으로 연결하기 위해 create_engine 함수 사용
이후, read_sql_query 함수로 SQL을 사용하여 데이터베이스에 질의, 그 결과를 데이터프레임으로 가져옴
# pip install sqlalchemy
import pandas as pd
from sqlalchemy import create_engine
# sample.db라는 데이터베이스에 연결
database_connection = create_engine('sqlite:///sample.db')
# sample.db에서 data라는 이름의 테이블의 모든 열을 반환하라고 요청
dataframe = pd.read_sql_query('SELECT * FROM data', database_connection)
# 모든 행을 가져올 때는 질의문 없이 read_sql_table() 함수도 사용 가능
dataframe = pd.read_sql_table('data', database_connection)