- 터미널에서 해당 명령어로 counter 폴더에 접근해준뒤 "pc init" 명령어로 pynecone 프로젝트 생성
- counter 폴더 안에 메인 파일인 counter.py가 생성됨
3. counter.py 작성
- 원래의 기본 코드는 다 지우고 counter app을 만들기 위해 기본 틀만 남김
from pcconfig import config
import pynecone as pc
# 각종 상태값을 정의하고 변경하기 위한 State 클래스
class State(pc.State):
pass
# 앱의 메인
def index():
return
# 앱 인스턴스 생성
# 페이지 추가
# 컴파일
app = pc.App(state=State)
app.add_page(index)
app.compile()
- pynecone 홈페이지의 코드 작성
from pcconfig import config
import pynecone as pc
# 각종 상태값을 정의하고 변경하기 위한 State 클래스
class State(pc.State):
# 변수는 모두 State에서 정의
count = 0
def increment(self):
self.count += 1
def decrement(self):
self.count -= 1
# 앱의 메인
def index():
return pc.hstack(
# 버튼을 클릭했을 때, State에서 정의한 decrement 함수가 실행
pc.button("desc - 1", on_click = State.decrement, color_scheme = "red", border_radius = "1em"),
# State에서 정의한 count 변수
pc.text(State.count),
# 버튼을 클릭했을 때, State에서 정의한 increment 함수가 실행
pc.button("asc + 1", on_click = State.increment, color_scheme = "green", border_radius = "1em"),
)
)
# 앱 인스턴스 생성
# 페이지 추가
# 컴파일
app = pc.App(state=State)
app.add_page(index)
app.compile()
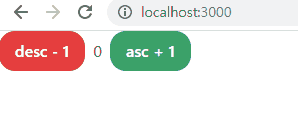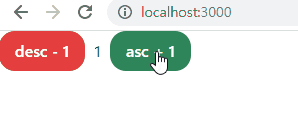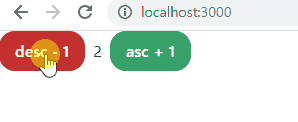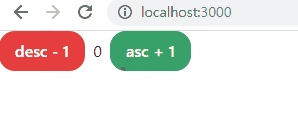
- 해당 페이지로 실행(pc run을 통해 한 번만 연결해두면 ctrl + s로 저장만 하면 자동으로 서버 재시작됨)
- 추가로 페이지의 중앙에 놓기, ±10 버튼 만들기 연습
from pcconfig import config
import pynecone as pc
# 각종 상태값을 정의하고 변경하기 위한 State 클래스
class State(pc.State):
# 변수는 모두 State에서 정의
count = 0
def increment(self):
self.count += 1
def increment_10(self):
self.count += 10
def decrement(self):
self.count -= 1
def decrement_10(self):
self.count -= 10
# 앱의 본체에 해당하는 함수(index)
def index():
return pc.center(
pc.hstack(
pc.button("desc - 10", on_click = State.decrement_10, color_scheme = "red", border_radius = "1em"),
pc.button("desc - 1", on_click = State.decrement, color_scheme = "red", border_radius = "1em"),
pc.text(State.count),
pc.button("asc + 1", on_click = State.increment, color_scheme = "green", border_radius = "1em"),
pc.button("asc + 10", on_click = State.increment_10, color_scheme = "green", border_radius = "1em"),
), padding = "50px"
)
# 앱의 인스턴스 생성
# 페이지 추가
# 컴파일
app = pc.App(state=State)
app.add_page(index)
app.compile()
# my_app이라는 폴더 생성
$ mkdir my_app
# 생성한 my_app 폴더로 현재 위치 이동
$ cd my_app
# 파이썬 가상환경 생성
$ python -m venv venv
# 가상환경 활성화
$ source venv/Scripts/activate
- pynecone 설치, node js 설치
pip install pynecone-io
# node js를 가상환경 별로 사용할 수 있게 해주는 패키지
pip install nodeenv
# 현재 가상환경에 독립된 nodejs 환경 추가
nodeenv -p
# nodejs 버전 잘 나오는지 확인
node -v
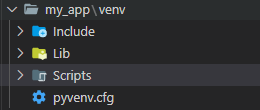
- 여기까지 만들어진 폴더
- 터미널에 "pc init" 명령어로 pynecone 프로젝트를 초기화 시켜주면 다음과 같은 폴더 구조가 생성됨
pc init
- 여기서 my_app.py가 메인 실행 파일
# my_app.py
"""Welcome to Pynecone! This file outlines the steps to create a basic app."""
from pcconfig import config
import pynecone as pc
docs_url = "https://pynecone.io/docs/getting-started/introduction"
filename = f"{config.app_name}/{config.app_name}.py"
class State(pc.State):
"""The app state."""
pass
def index():
return pc.center(
pc.vstack(
pc.heading("Welcome to Pynecone!", font_size="2em"),
pc.box("Get started by editing ", pc.code(filename, font_size="1em")),
pc.link(
"Check out our docs!",
href=docs_url,
border="0.1em solid",
padding="0.5em",
border_radius="0.5em",
_hover={
"color": "rgb(107,99,246)",
},
),
spacing="1.5em",
font_size="2em",
),
padding_top="10%",
)
# Add state and page to the app.
app = pc.App(state=State)
app.add_page(index)
app.compile()
- 터미널에 "pc run" 명령어 실행하면 서버 열림
pc run
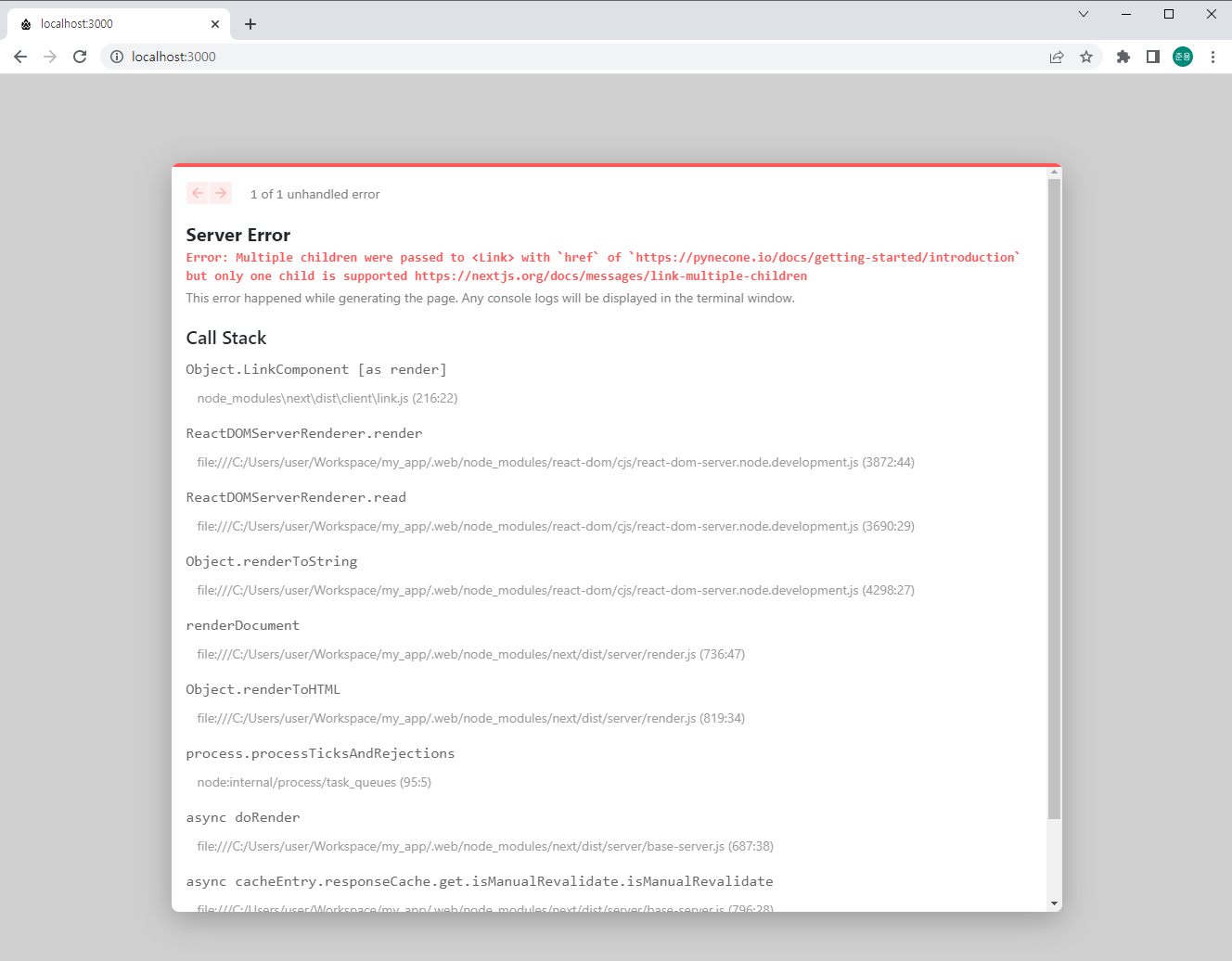
- localhost:3000을 통해 접속(오류가 뜨기는 하지만 정상)
- my_app.py 파일을 다음과 같이 변경하여 다시 "pc run"을 실행해보면 아래의 페이지가 정상적으로 출력됨
from pcconfig import config
import pynecone as pc
class State(pc.State):
pass
def index():
return pc.text("Hello World")
app = pc.App(state=State)
app.add_page(index)
app.compile()
# 필요 라이브러리
import pandas as pd
import numpy as np
import graphviz
import multiprocessing
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris, load_wine, load_breast_cancer, load_diabetes
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
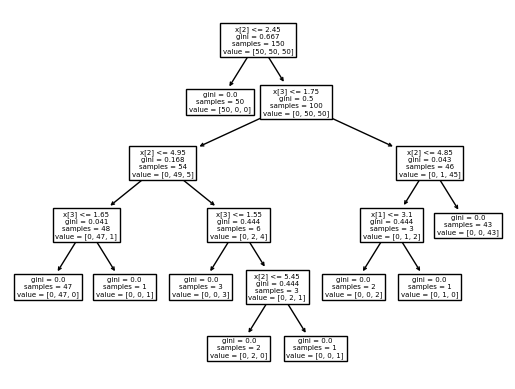
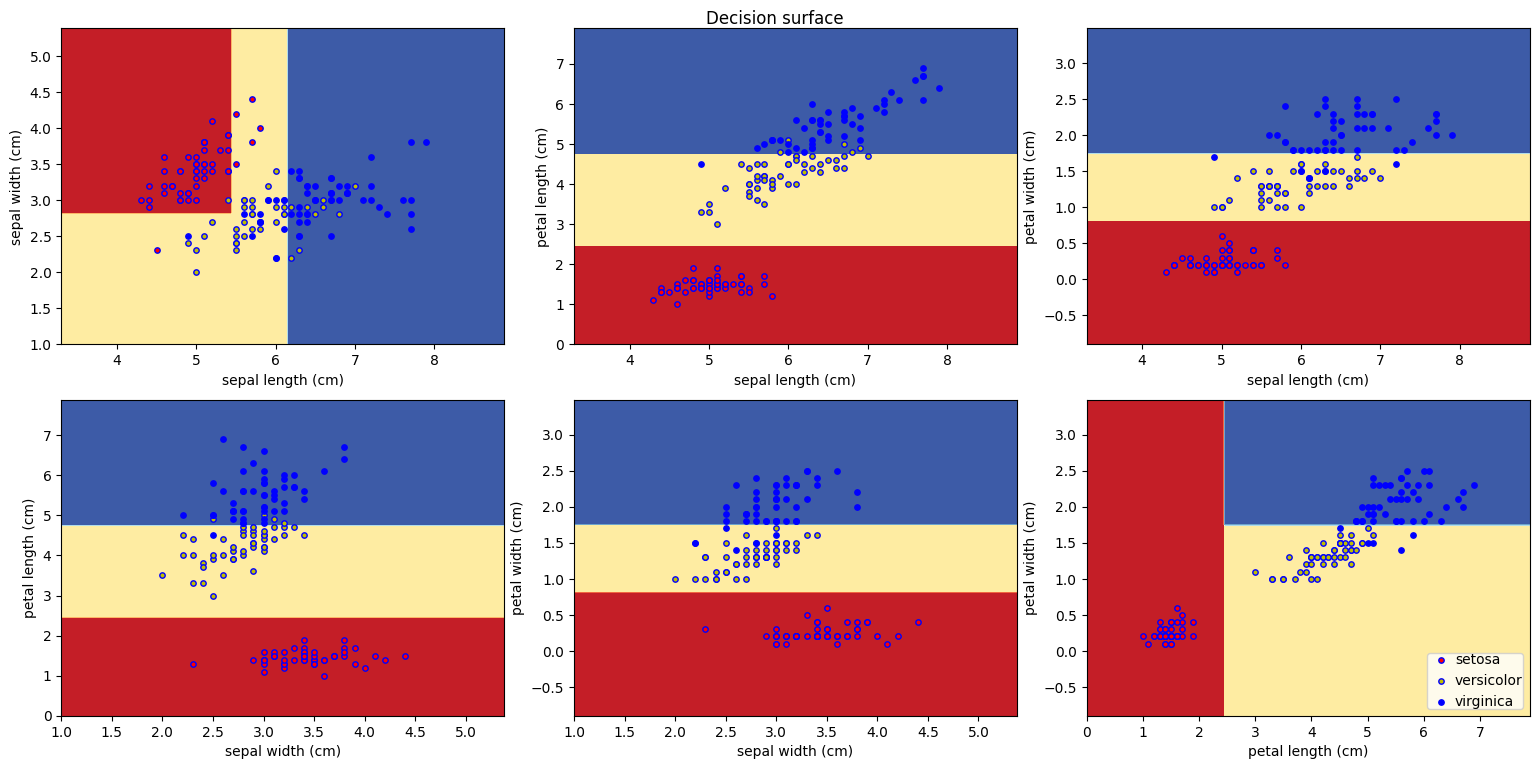
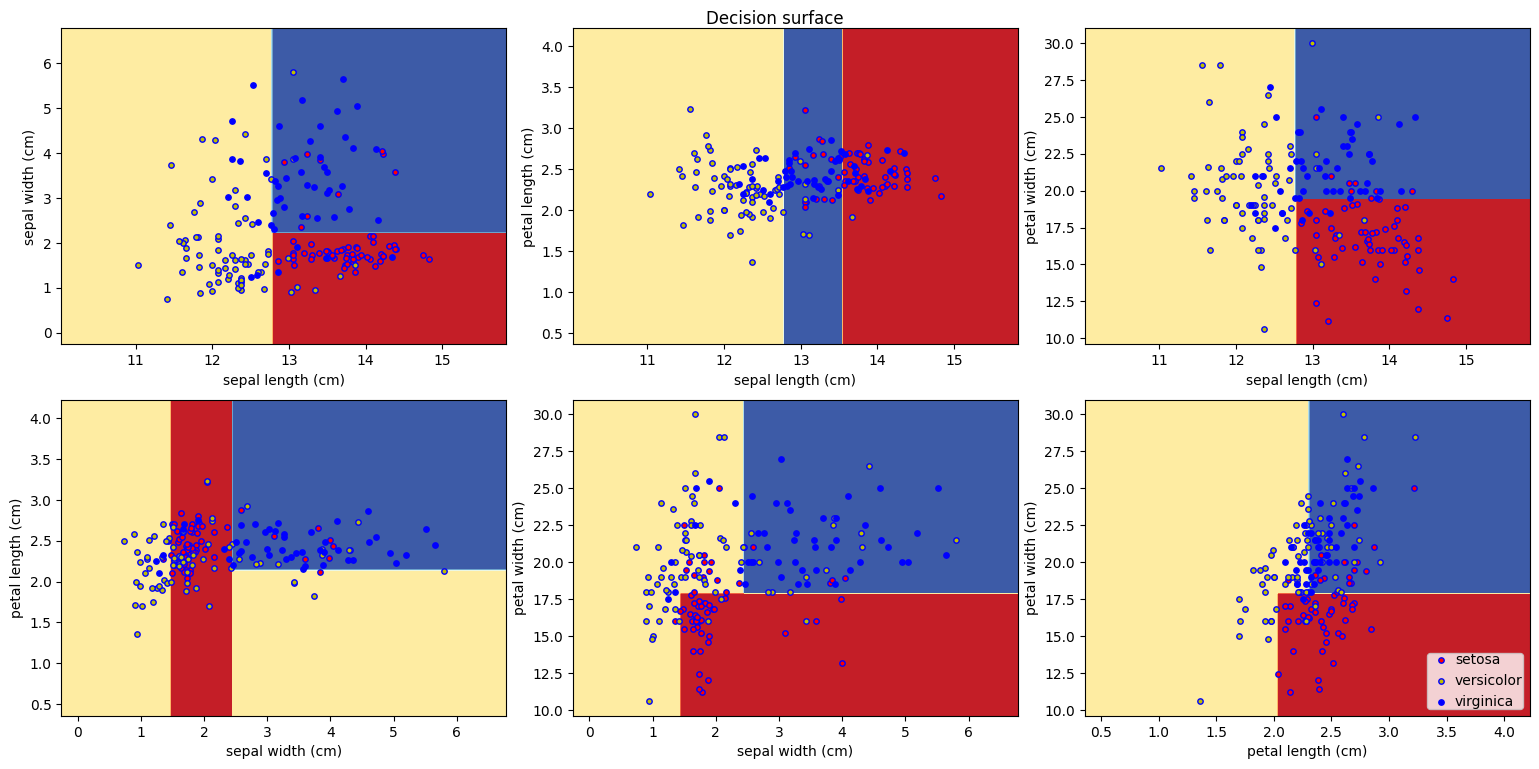
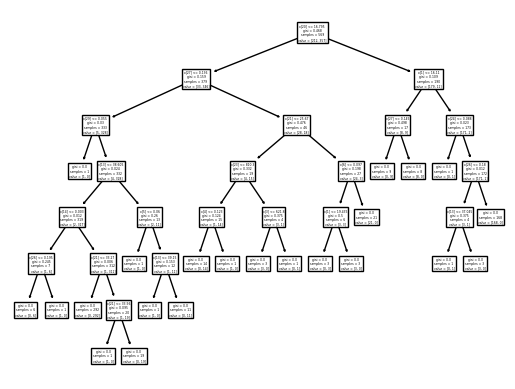
1. 결정 트리를 활용한 분류(DecisionTreeClassifier())
DecisionTreeClassifier는 분류를 위한 결정 트리 모델
두 개의 배열 X, y를 입력받음
X는 [n_samples, n_features] 크기의 데이터 특성 배열
y는 [n_samples] 크기의 정답 배열
X = [[0, 0], [1, 1]]
y = [0, 1]
# X가 [0, 0]일 때는 y가 0, X가 [1, 1]일 때는 y가 1 과 같이 분류
model = tree.DecisionTreeClassifier()
model = model.fit(X, y)
# X에 [2, 2]를 줬을 때 0과 1 중 어디로 분류될 지
model.predict([[2., 2.]])
# 출력 결과
array([1]) # 1로 분류됨
# X에 [2, 2]를 줬을 때 0과 1에 각각 분류될 확률
model.predict_proba([[2., 2.]])
# 출력 결과
array([[0., 1.]]) # 1이 선택될 확률이 100%로 나옴
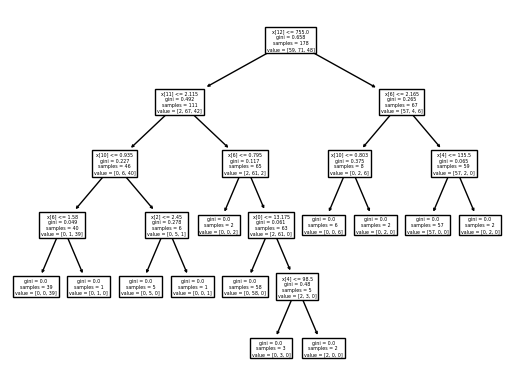
1) 붓꽃 데이터 분류(전처리 x)
model = DecisionTreeClassifier()
cross_val_score(
estimator = model,
X = iris.data, y = iris.target,
cv = 5,
n_jobs = multiprocessing.cpu_count()
)
# 출력 결과
array([0.96666667, 0.96666667, 0.9 , 1. , 1. ])
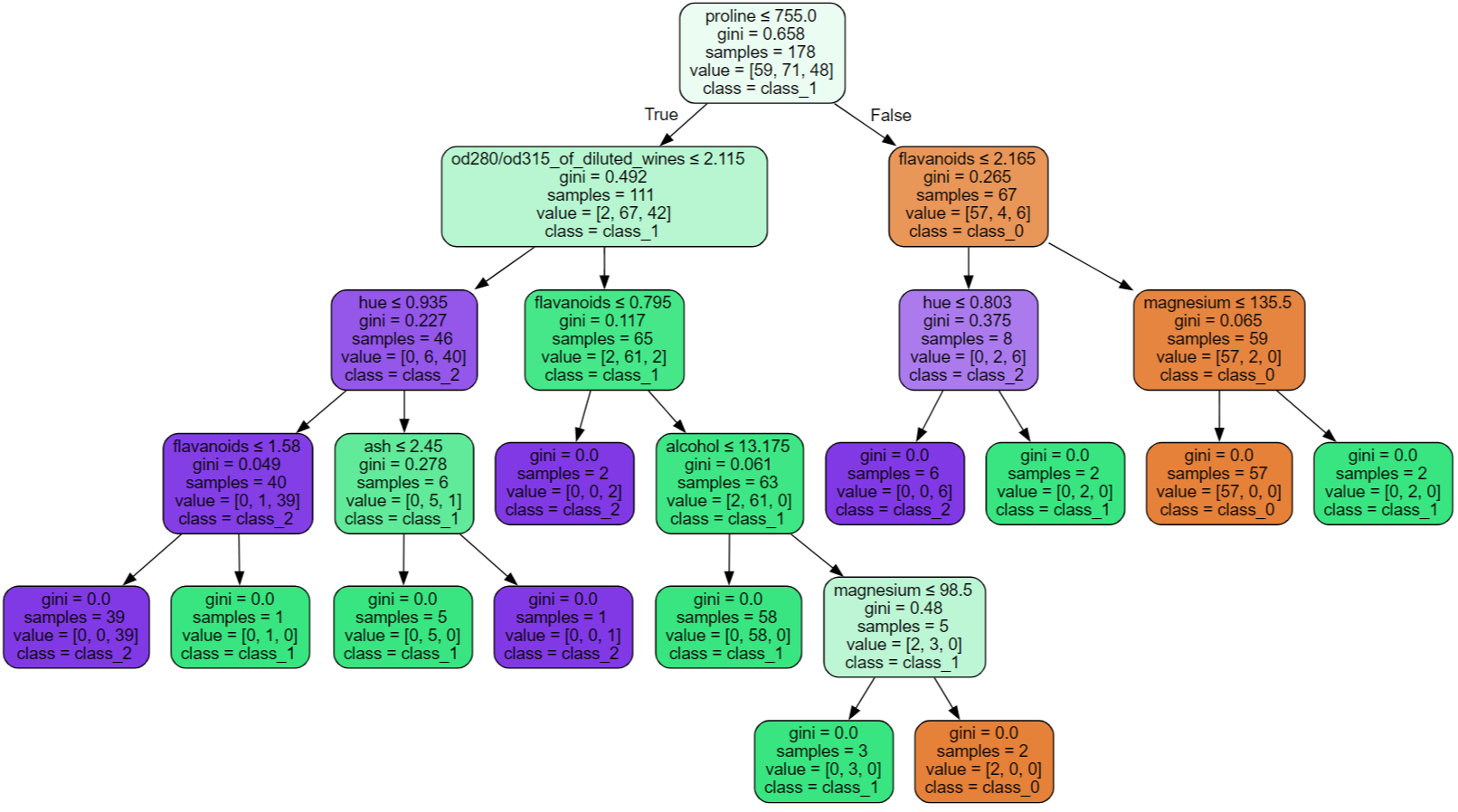
2) 붓꽃 데이터 분류(전처리 o)
model = make_pipeline(
StandardScaler(),
DecisionTreeClassifier()
)
cross_val_score(
estimator = model,
X = iris.data, y = iris.target,
cv = 5,
n_jobs = multiprocessing.cpu_count()
)
# 출력 결과
array([0.96666667, 0.96666667, 0.9 , 1. , 1. ])
- 전처리 한 것과 하지 않은 것의 결과에 차이가 없는데, 결정 트리는 규칙을 학습하기 때문에 전처리에 큰 영향을 받지 않음
HttpServletRequest / HttpServletResponse 이용하지 않아도 될 만큼 추상화된 방식으로 개발 가능
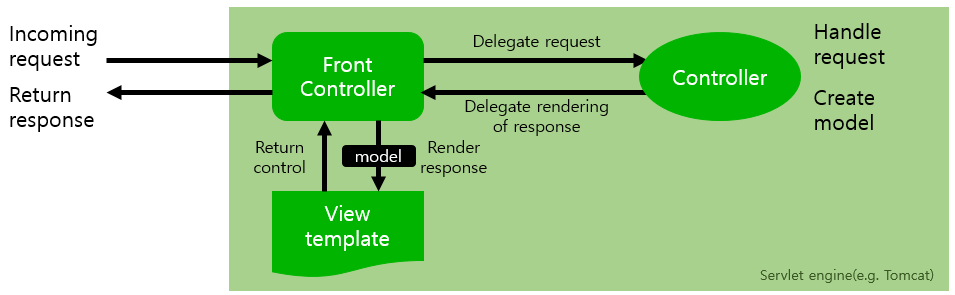
스프링 MVC의 전체 흐름
1) DispatcherServlet과 Front Controller
스프링 MVC의 모든 요청은 반드시 DispatcherServlet이라는 존재를 통해서 실행됨
Front-Controller 패턴을 이용하면 모든 요청이 반드시 하나의 객체를 지나서 처리되어 모든 공통적인 처리를 Front-Controller에서 처리 가능
스프링 MVC에서 DispatcherServlet이라는 객체가 Front-Controller 역할 수행
Front-Controller가 사전 / 사후에 대한 처리를 하게 되면 중간에 매번 다른 처리를 하는 부분만 별도로 처리하는 구조를 만들게 됨(이 부분이 Controller이고 @Controller를 이용해서 처리)
실습
1) 스프링 MVC 사용하기
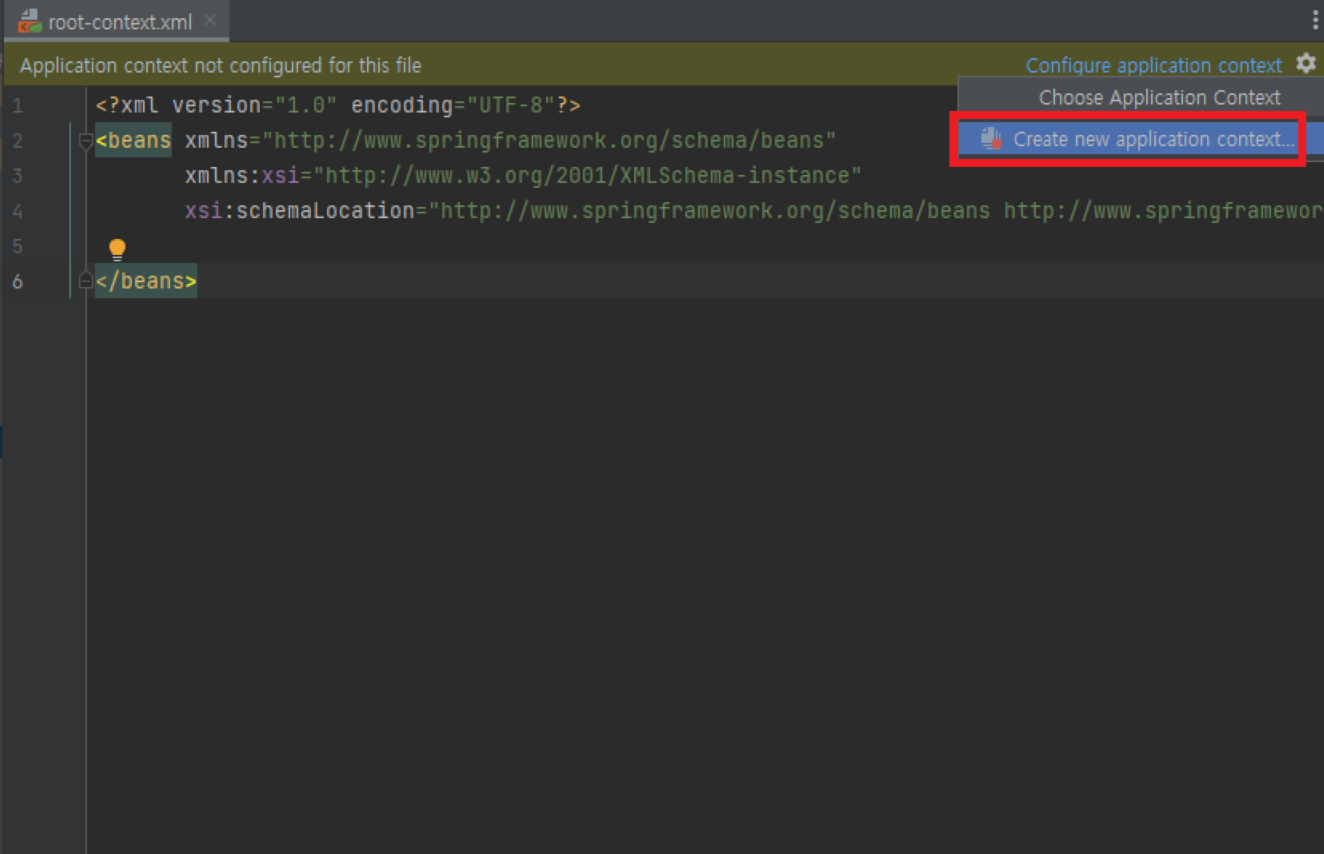
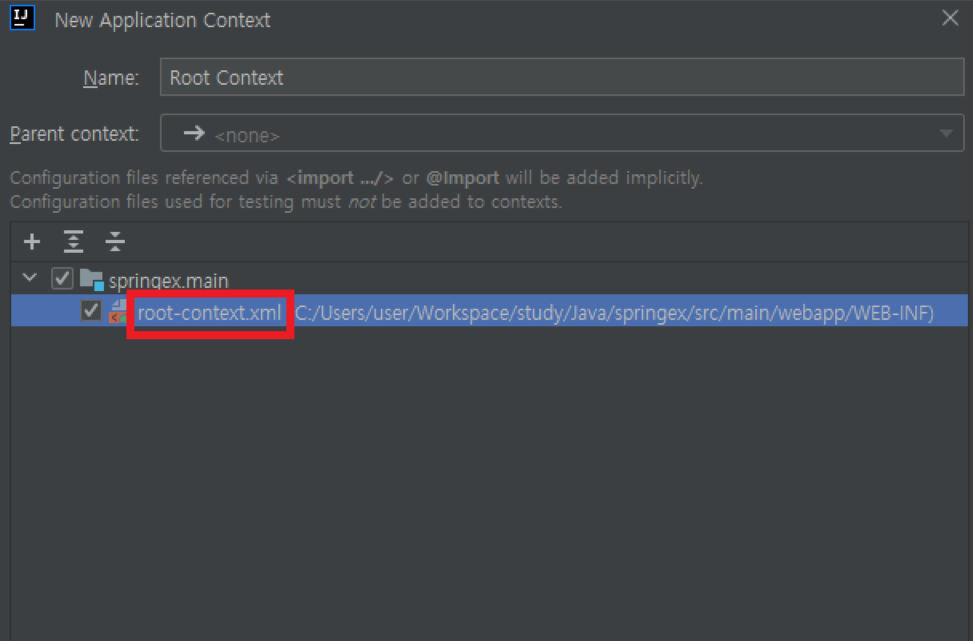
- 프로젝트의 webapp 폴더 > resources 폴더 생성: 이미지나 html 파일 같은 정적인 파일을 서비스하기 위한 경로
- webapp 폴더 > WEB-INF > servlet-context.xml 생성
<!-- servlet-context.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns = "http://www.springframework.org/schema/beans"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:mvc = "http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd">
<!-- 스프링 MVC 설정을 어노테이션 기반으로 처리한다는 의미, 스프링 MVC의 여러 객체들을 자동을 ㅗ스프링의 Bean으로 등록하게 하는 기능 -->
<mvc:annotation-driven></mvc:annotation-driven>
<!-- 이미지나 html 파일 같은 정적인 파일 경로 지정 -->
<!-- "/resources" 경로로 들어오는 요청은 정적인 파일을 요구하는 것으로 판단하고 스프링 MVC에서 처리하지 않는다는 의미 -->
<mvc:resources mapping = "/resources/**" location = "/resources/"></mvc:resources>
<!-- InternalResourceViewResolver는 스프링 MVC에서 제공하는 View를 어떻게 결정하는지에 대한 설정 담당 -->
<bean class = "org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name = "prefix" value = "/WEB-INF/views/"></property>
<property name = "suffix" value = ".jsp"></property>
</bean>
</beans>
2) web.xml의 DispatcherServlet 설정
스프링 MVC 실행을 위해 Front-Controller 역할을 하는 DispatcherServlet 설정
<!-- web.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
...
<!-- DispatcherServlet 로딩 시 servlet-context.xml을 이용하도록 설정 -->
<servlet>
<servlet-name>appServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/servlet-context.xml</param-value>
</init-param>
<!-- Tomcat 로딩 시 클래스를 미리 로딩해두기 위한 설정 -->
<load-on-startup>1</load-on-startup>
</servlet>
<!-- DispatcherServlet이 모든 경로의 요청에 대한 처리를 담당하기 때문에 '/'fh wlwjd -->
<servlet-mapping>
<servlet-name>appServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
실습
2) 스프링 MVC Controller
- 스프링 MVC Controller의 다른 점
상속이나 인터페이스를 구현하는 방식을 사용하지 않고 어노테이션만으로 처리 가능
오버라이드 없이 필요한 메서드 정의
메서드의 파라미터를 기본 자료형이나 객체 자료형을 마음대로 지정
메서드의 리턴타입도 void, String, 객체 등 다양한 타입 사용 가능
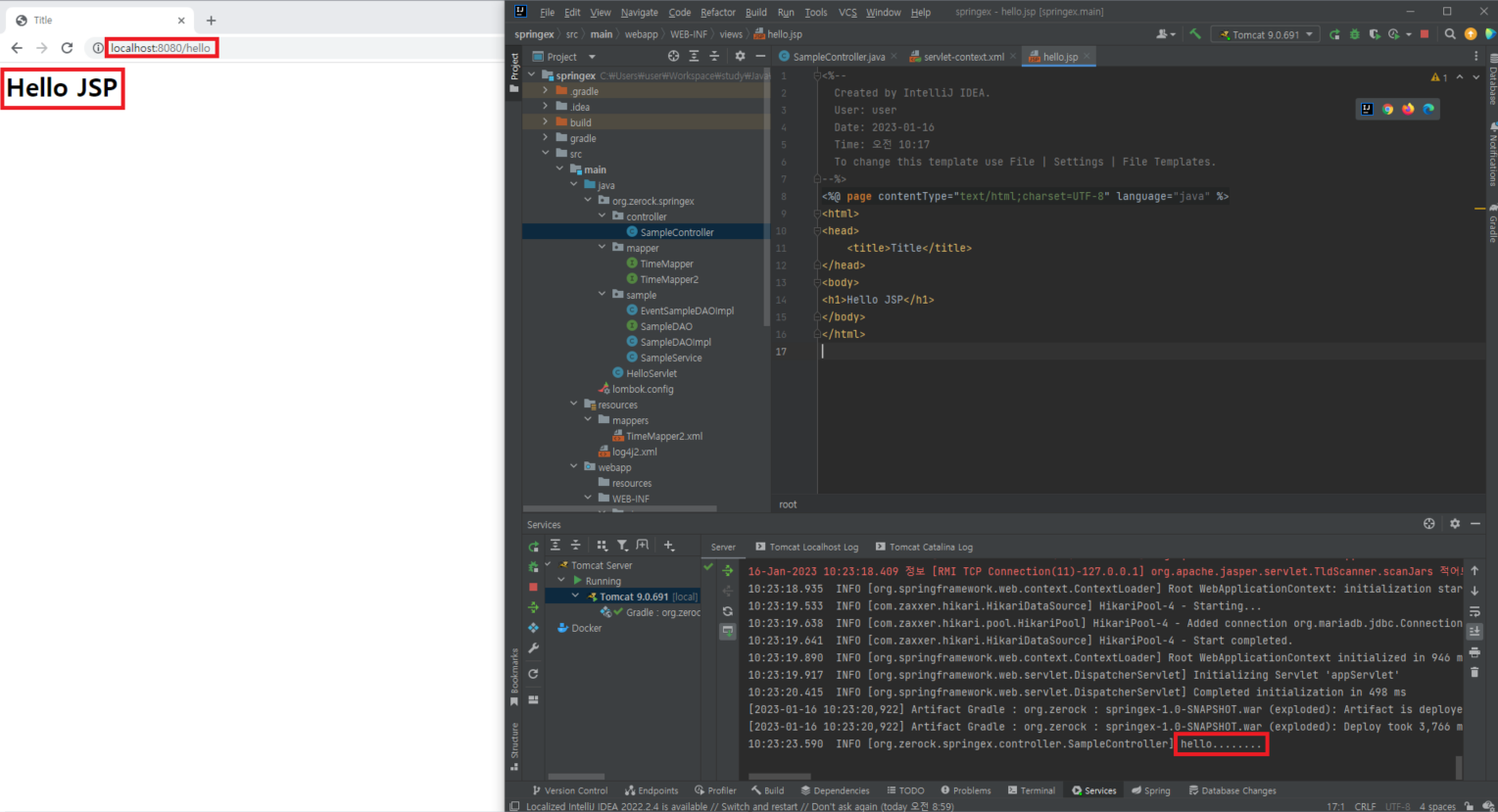
- org.zerock.springex 프로젝트 내에 controller 패키지 추가 > SampleController 클래스 추가
// SampleController
package org.zerock.springex.controller;
import lombok.extern.log4j.Log4j2;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
// 해당 클래스가 MVC에서 Controller 역할을 한다는 의미, 스프링의 Bean으로 처리되기 위해 사용
@Controller
@Log4j2
public class SampleController {
// GET 방식으로 들어오는 요청을 처리하기 위해 사용("/hello"라는 경로를 호출할 때 동작)
@GetMapping("/hello")
public void hello() {
log.info("hello........" );
}
}
3) servlet-context.xml의 component-scan
controller 패키지에 존재하는 Controller 클래스들을 스프링으로 인식하기 위해 @Controller 어노테이션이 추가된 클래스들의 객체들이 스프링의 Bean으로 설정되게 만들어야 함
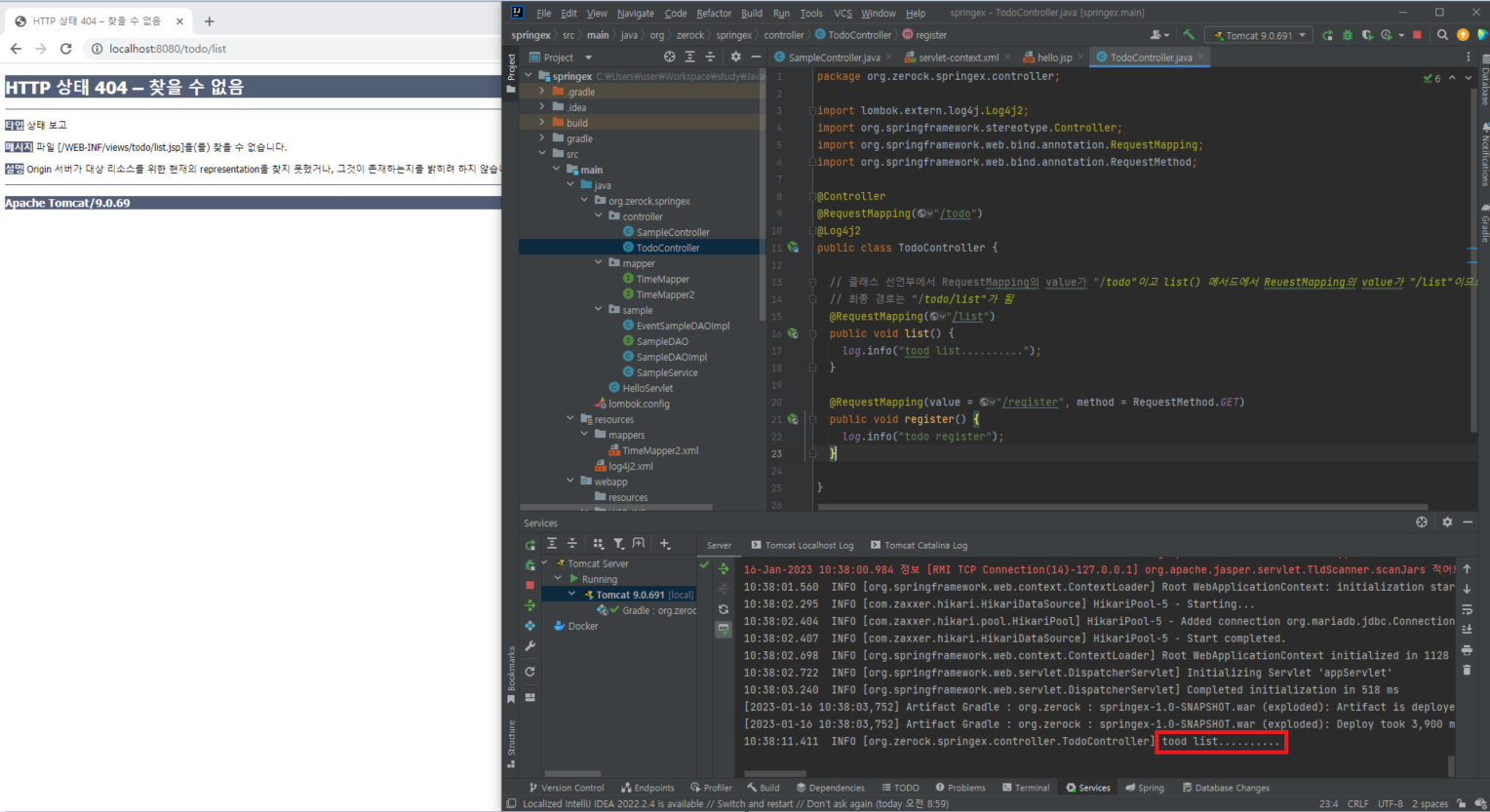
/todo/list 경로의 화면을 만들지 않아서 화면을 띄우는 것은 오류가 나지만, 로그에 list() 메서드가 실행되어 메세지가 뜬 것을 확인
@RequestMapping을 이용하는 것만으로 여러 Controller를 하나의 클래스로 묶을 수 있고, 각 기능마다 메서드 단위로 설계할 수 있게 되어 많은 양의 코드 줄일 수 있음
스프링 4버전 이후에는 @GetMapping / @PostMapping 어노테이션으로 GET/ POST 방식 구분해서 처리 가능
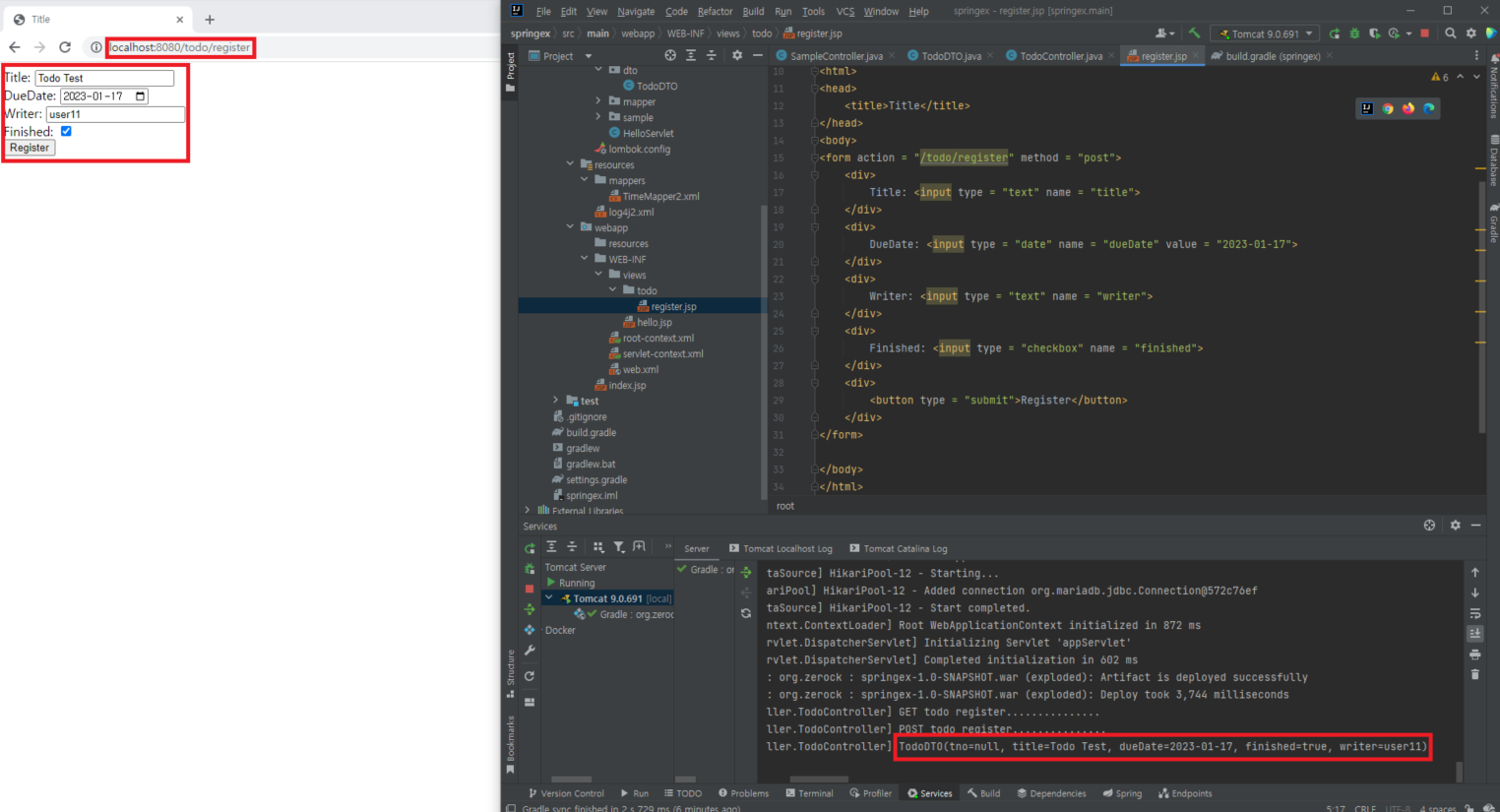
예를 들어, "/todo/register"는 GET 방식으로 화면을 보여주고, POST 방식으로 처리하므로 다음과 같이 설계
// TodoController
package org.zerock.springex.controller;
import ...
@Controller
@RequestMapping("/todo")
@Log4j2
public class TodoController {
// 클래스 선언부에서 RequestMapping의 value가 "/todo"이고 list() 메서드에서 ReuestMapping의 value가 "/list"이므로
// 최종 경로는 "/todo/list"가 됨
@RequestMapping("/list")
public void list() {
log.info("tood list..........");
}
// @RequestMapping(value = "/register", method = RequestMethod.GET)
@GetMapping("/register")
public void registerGET() {
log.info("GET todo register...............");
}
@PostMapping("/register")
public void registerPOST() {
log.info("POST todo register...............");
}
}
2. 파라미터 자동 수집과 변환
파라미터 자동 수집은 DTO, VO 등을 메서드의 파라미터로 설정하면 자동으로 전달되는 HttpServletRequest의 파라미터들을 수집해주는 기능
단순 문자열만이 아니라 숫자, 배열, 리스트, 첨부 파일도 가능
파라미터 수집 동작 기준
기본 자료형의 경우 자동으로 형 변환처리 가능
객체 자료형의 경루 setXXX()를 통해 처리
객체 자료형의 경우 생성자가 없거나 파라미터가 없는 생성자가 필요(Bean)
실습
3) 단순 파라미터의 자동 수집
- SampleController에서의 예시
// SampleController
package org.zerock.springex.controller;
import ...
// 해당 클래스가 MVC에서 Controller 역할을 한다는 의미, 스프링의 Bean으로 처리되기 위해 사용
@Controller
@Log4j2
public class SampleController {
...
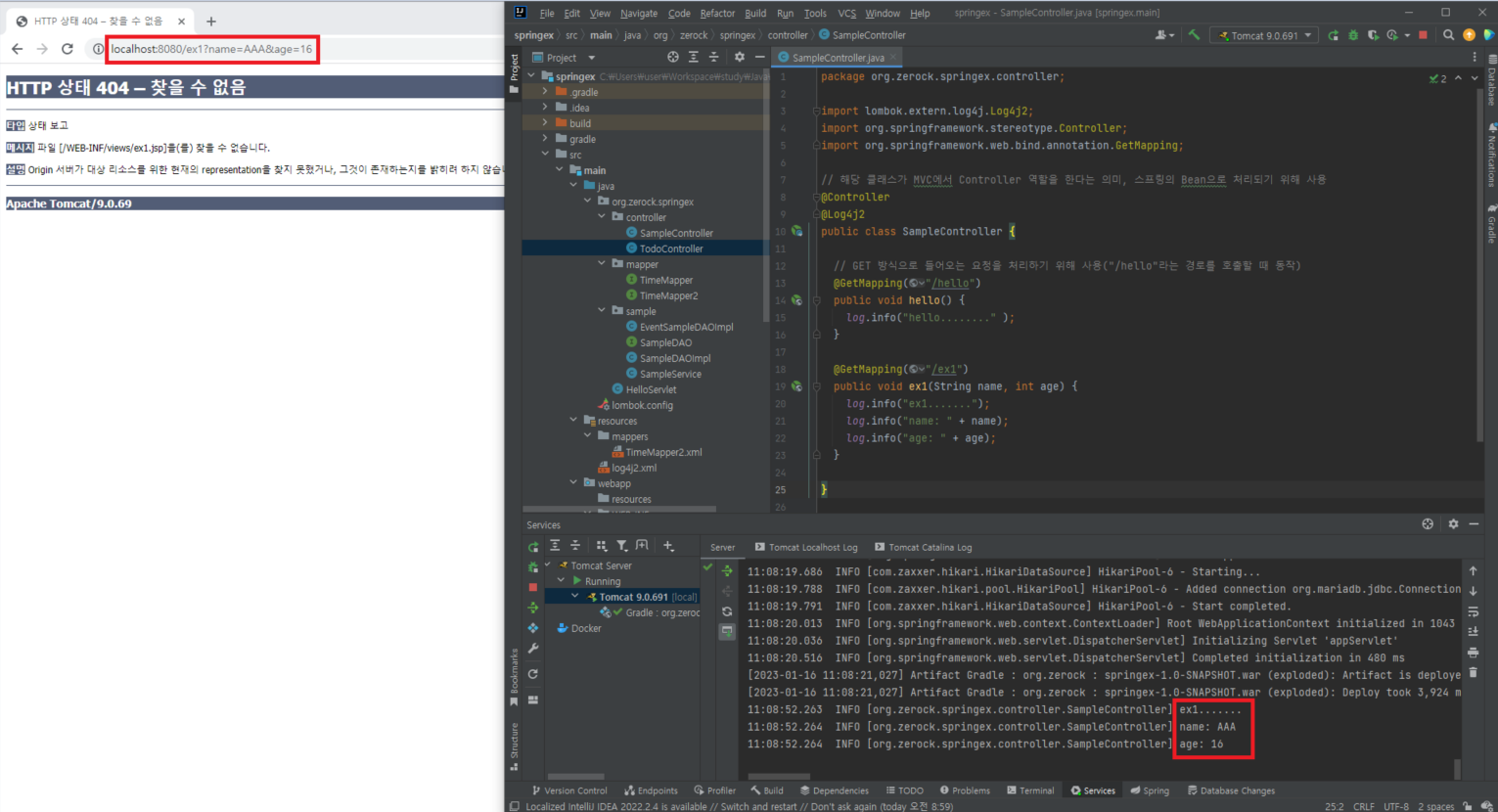
@GetMapping("/ex1")
public void ex1(String name, int age) {
log.info("ex1.......");
log.info("name: " + name);
log.info("age: " + age);
}
}
- 주소를 "http://localhost:8080/ex1?name=AAA&age=16"로 설정하면 자동으로 name은 문자열 AAA로, age는 숫자 16으로 파라미터를 수집해와서 로그에 출력
- @RequestParam
- 요청에 전달된 파라미터 이름을 기준으로 동작하지만, 간혹 파라미터가 전달되지 않으면 문제 발생할 수 있음
- 이 때 @RequestParam이라는 어노테이션 고려
- @RequestParam은 defaultValue라는 속성이 있어서 '기본값'을 지정할 수 있음
package org.zerock.springex.controller;
import ...
// 해당 클래스가 MVC에서 Controller 역할을 한다는 의미, 스프링의 Bean으로 처리되기 위해 사용
@Controller
@Log4j2
public class SampleController {
...
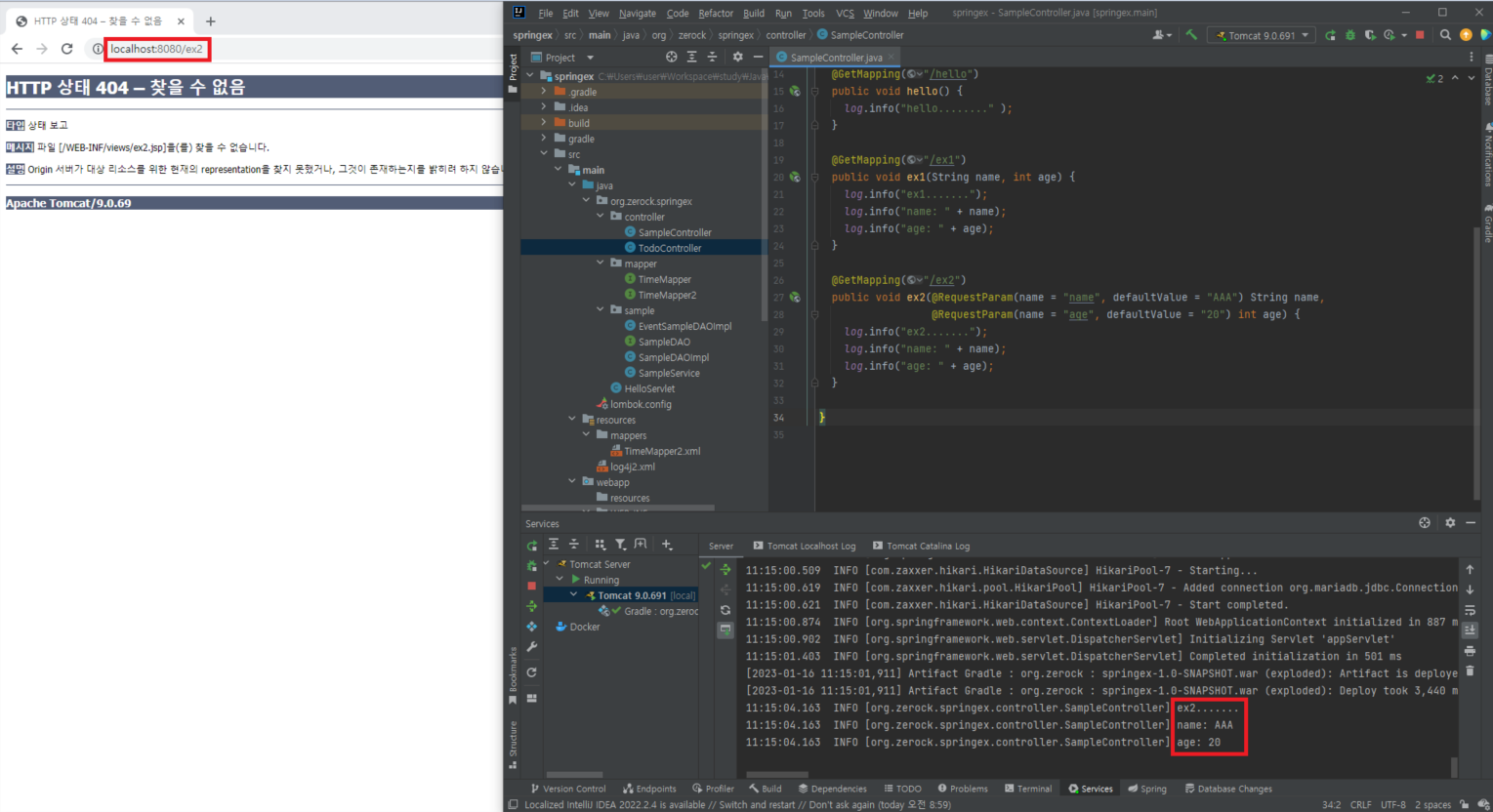
@GetMapping("/ex2")
public void ex2(@RequestParam(name = "name", defaultValue = "AAA") String name,
@RequestParam(name = "age", defaultValue = "20") int age) {
log.info("ex2.......");
log.info("name: " + name);
log.info("age: " + age);
}
}
- 주소에 "http://localhost:8080/ex2"만 입력하고 파라미터를 주지 않아도 기본값으로 파라미터를 받아서 로그로 출력함
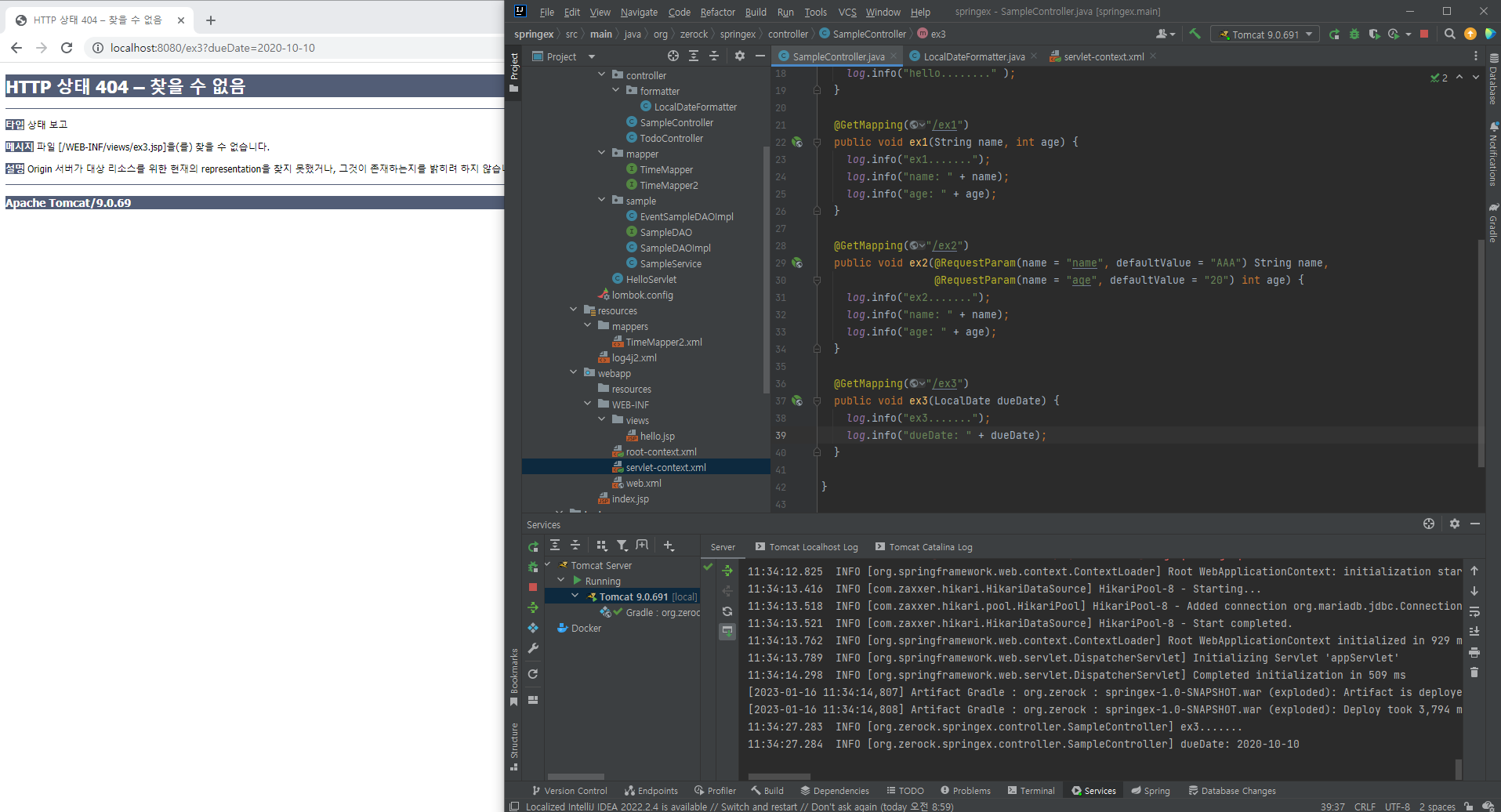
- Formatter를 이용한 파라미터의 커스텀 처리
- 기본적으로 HTTP는 문자열로 데이터를 전달하기 때문에 Controller는 문자열을 기준으로 특정 클래스의 객체로 처리하는 작업이 진행
ex5 호출하면 name과 result라는 이름을 가진 값들이 생성되어 ex6으로 redirect됨
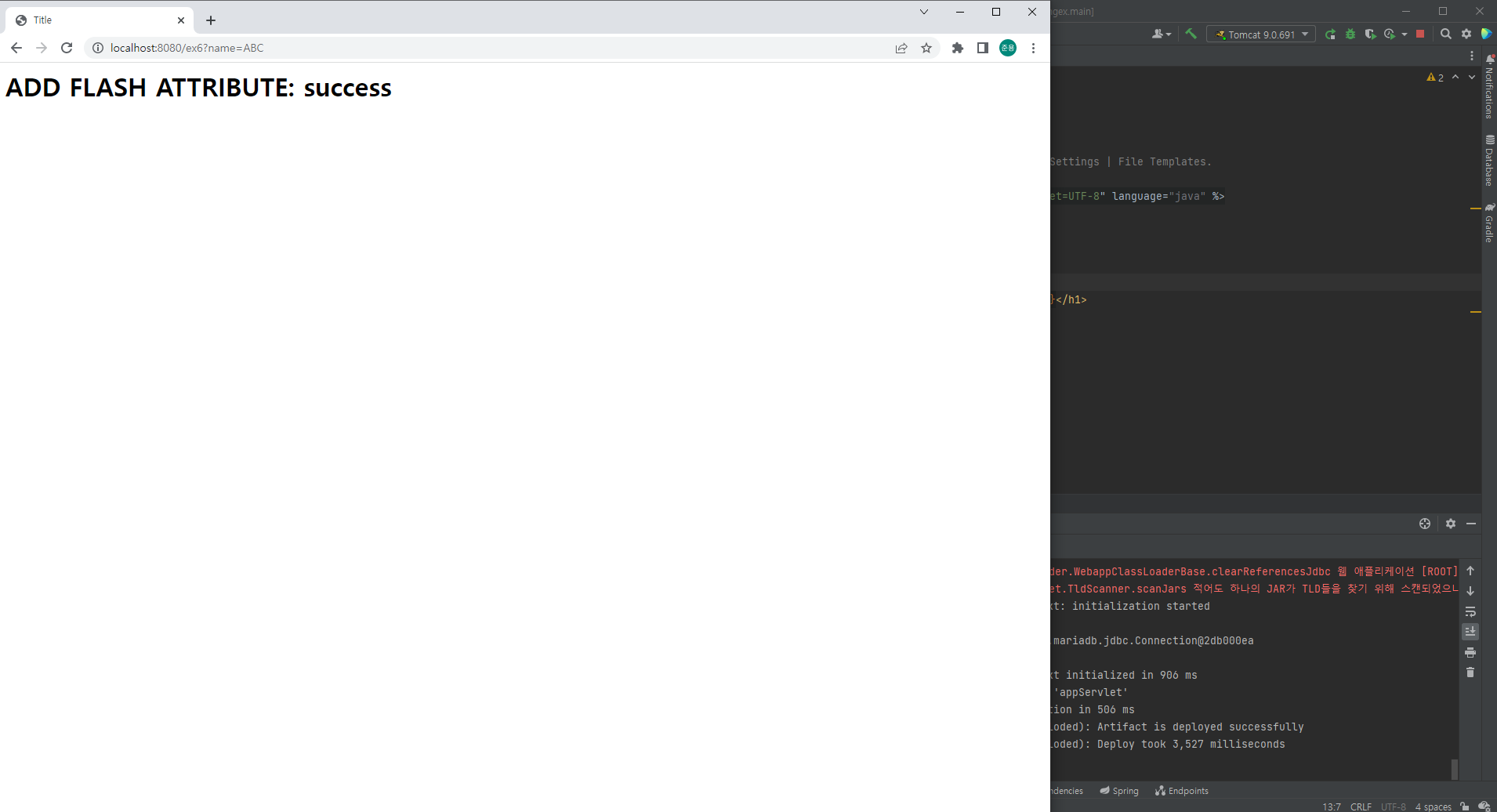
ex6의 화면이 나오고 쿼리 스트링으로 준 name의 값 "ABC"가 주소창에 전달되어 있고, 화면에 ${result}로 출력한 result의 값인 "success"가 출력되어 있음
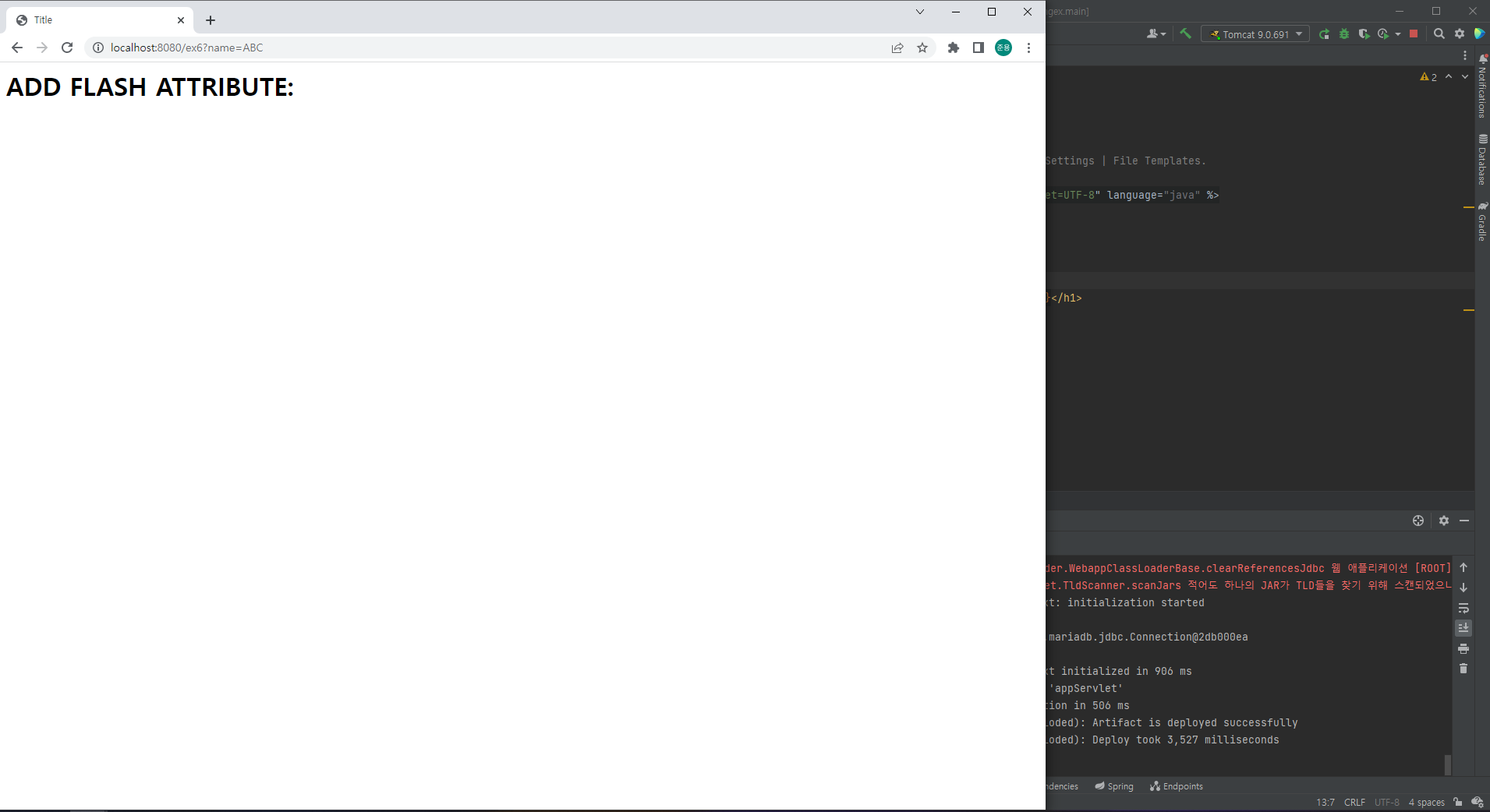
addFlashAttribute는 일회용으로 전달하고 사라지므로, 해당 페이지를 새로고침하면, "success"가 사라짐을 확인
4) 다양한 리턴 타입
스프링 MVC에서 Controller내에 선언하는 메서드의 리턴 타입을 다양하게 사용 가능
void: 화면이 따로 있는 경우, @RequestMapping값 과 @GetMapping 등 메서드에서 선언된 값을 그대로 View의 이름으로 사용, 주로 상황에 관계없이 동일한 화면을 보여줄 때 사용
문자열: 화면이 따로 있는 경우, 상황에 따라 다른 화면 보여줄 때 사용, 다음과 같은 특별한 접두어 사용가능
redirect: 리다이렉션을 이용하는 경우, 주로 forward 대신 redirect 이용
forward: 브라우저의 URL은 고정하고 내부적으로 다른 URL로 처리하는 경우
객체나 배열, 기본 자료형: JSON 타입 활용 시
ResponseEntity: JSON 타입 활용 시
5) 스프링 MVC에서 주로 사용하는 어노테이션
Controller 선언부에 사용하는 어노테이션
@Controller: 스프링 Bean의 처리됨을 명시
@RestController: REST 방식의 처리를 위한 Controller임을 명시
@RequestMapping: 특정한 URL 패턴에 맞는 Controller인지를 명시
메서드 선언부에 사용하는 어노테이션
@GetMapping / @PostMapping / @DeleteMapping / @PutMapping ...: HTTP 전송방식에 따라 해당 메서드를 지정하는 경우 사용, 일반적으로 @GetMapping과 @PostMapping을 주로 사용
@RequestMapping: GET / POST 방식 모두 지원하는 경우 사용
@ResponseBody: REST 방식에서 사용
메서드의 파라미터에 사용하는 어노테이션
@RequestParam: Request에 있는 특정한 이름의 데이터를 파라미터로 받아서 처리하는 경우 사용
@PathVariable: URL 경로의 일부를 변수로 삼아서 처리하기 위해 사용
@ModelAttribute: 해당 파라미터는 반드시 Model에 포함되어 다시 View로 전달됨을 명시(주로 기본 자료형이나 Wrapper 클래스, 문자열에 사용)
기타: @SessionAttribute, @Valid, @RequestBody 등
3. 스프링 MVC의 예외 처리
스프링 MVC에서 예외를 처리하는 가장 일반적인 방법은 @ControllerAdvice를 이용하는 것
@ControllerAdvice는 Controller에서 발생하는 예외에 맞게 처리할 수 있는 기능 제공
@ControllerAdvice가 선언된 클래스 역시 스프링의 Bean으로 처리됨
실습을 위해 controller 패키지 > exception 패키지 > CommonExceptionAdvice 클래스 작성
// CommonExceptionAdvice
package org.zerock.springex.controller.exception;
import lombok.extern.log4j.Log4j2;
import org.springframework.web.bind.annotation.ControllerAdvice;
@ControllerAdvice
@Log4j2
public class CommonExceptionAdvice {
}
1) @ExceptionHandler
@ControllerAdvice의 메서드들에는 특별하게 @ExceptionHandler라는 어노테이션 사용 가능
이를 이용해서 전달되는 Exception 객체들을 지정하고 메서드의 파라미터에서 이를 이용 가능
고의로예외를 발생시키는 코드 작성하여 실험
// SampleController
package org.zerock.springex.controller;
import ...
@Controller
@Log4j2
public class SampleController {
...
// p1에는 문자열이, p2에는 숫자가 전달되어야 함
@GetMapping("/ex7")
public void ex7(String p1, int p2) {
log.info("p1........" + p1);
log.info("p2........" + p2);
}
}
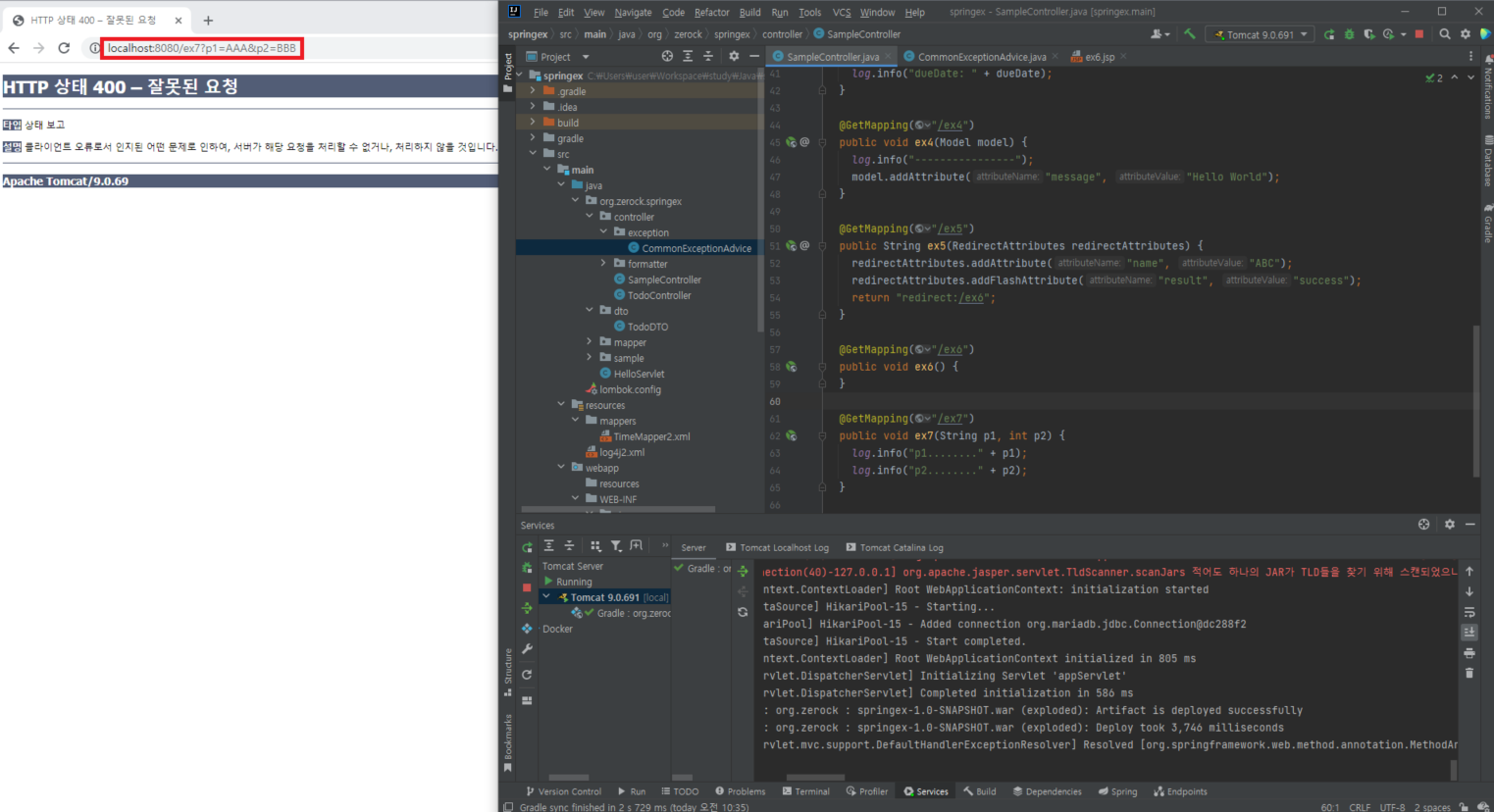
해당 코드를 작성하고, p2에 숫자가 아닌 문자열을 쿼리 스트링으로 전달해주면 예외가 발생
"localhost:8080/ex7?p1=AAA&p2=BBB"를 주면 BBB는 int형이 아니므로 에러 코드 400이 발생
해결을 위해 CommonExceptionAdvice에 NumberFormatException을 처리하도록 지정
// CommonExceptionAdvice
package org.zerock.springex.controller.exception;
import lombok.extern.log4j.Log4j2;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
@ControllerAdvice
@Log4j2
public class CommonExceptionAdvice {
// 문자열이나 JSON 데이터를 그대로 전송할 때 사용되는 어노테이션
@ResponseBody
// @ExceptionHandler를 가진 모든 메서드는 해당 타입의 예외를 파라미터로 전달받을 수 있음
@ExceptionHandler(NumberFormatException.class)
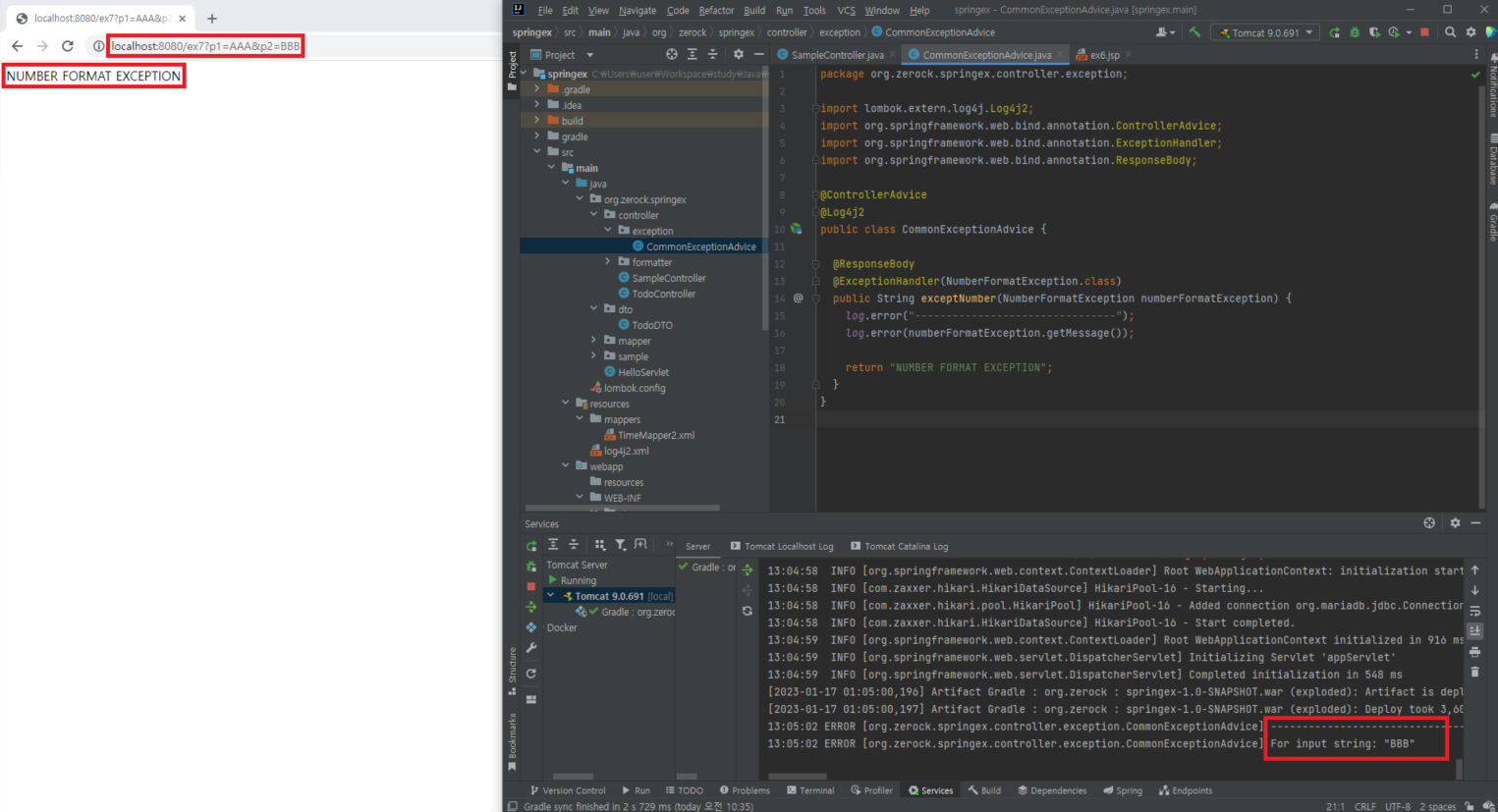
// exceptNumber()는 @ResponseBody를 이용해서 만들어진 문자열을 그대로 브라우저에 전송하는 방식 이용
public String exceptNumber(NumberFormatException numberFormatException) {
log.error("--------------------------------");
log.error(numberFormatException.getMessage());
return "NUMBER FORMAT EXCEPTION";
}
}
2) 범용적인 예외처리
예외 처리의 상위 타입인 Excpetion 타입을 처리하도록 구성
// CommonExceptionAdvice
package org.zerock.springex.controller.exception;
import lombok.extern.log4j.Log4j2;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.Arrays;
@ControllerAdvice
@Log4j2
public class CommonExceptionAdvice {
// 문자열이나 JSON 데이터를 그대로 전송할 때 사용되는 어노테이션
@ResponseBody
// @ExceptionHandler를 가진 모든 메서드는 해당 타입의 예외를 파라미터로 전달받을 수 있음
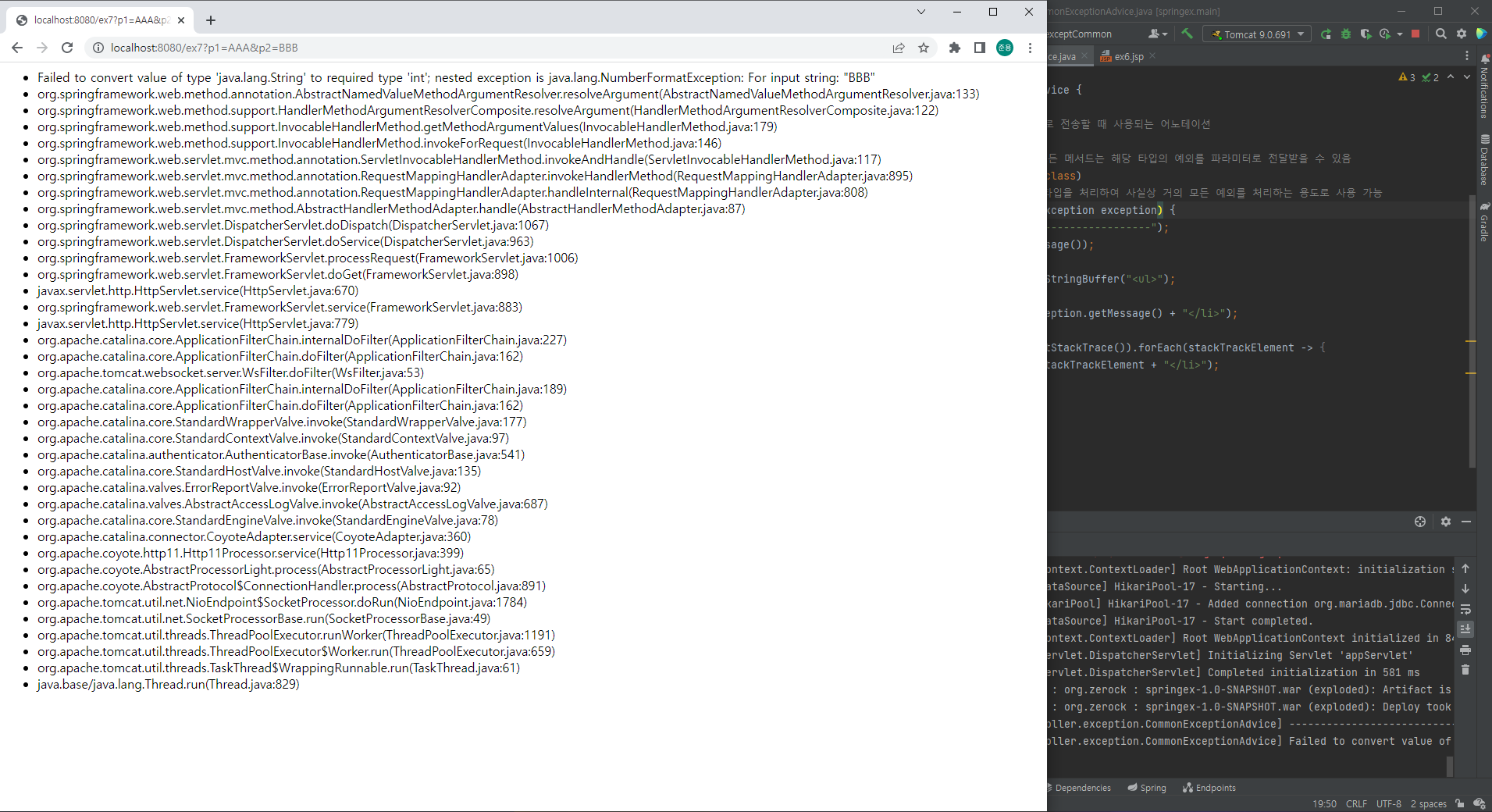
@ExceptionHandler(Exception.class)
// exceptCommon은 Exception 타입을 처리하여 사실상 거의 모든 예외를 처리하는 용도로 사용 가능
public String exceptCommon(Exception exception) {
log.error("--------------------------------");
log.error(exception.getMessage());
// <ul>로 시작하는 buffer 문자열 작성
StringBuffer buffer = new StringBuffer("<ul>");
// 예외 처리 메세지가 발생할 때마다 <li>와 함께 <ul></ul> 안에 리스트 형태로 해당 메세지를 추가
buffer.append("<li>" + exception.getMessage() + "</li>");
// 에러가 났을 때, 현재의 함수나 메서드 명도 같이 출력하여 더 자세히 디버깅할 수 있도록 함
Arrays.stream(exception.getStackTrace()).forEach(stackTrackElement -> {
buffer.append("<li>" + stackTrackElement + "</li>");
});
// 마지막에는 리스트 형식을 끝내도록 </ul> 추가
buffer.append("</ul>");
return buffer.toString();
}
}
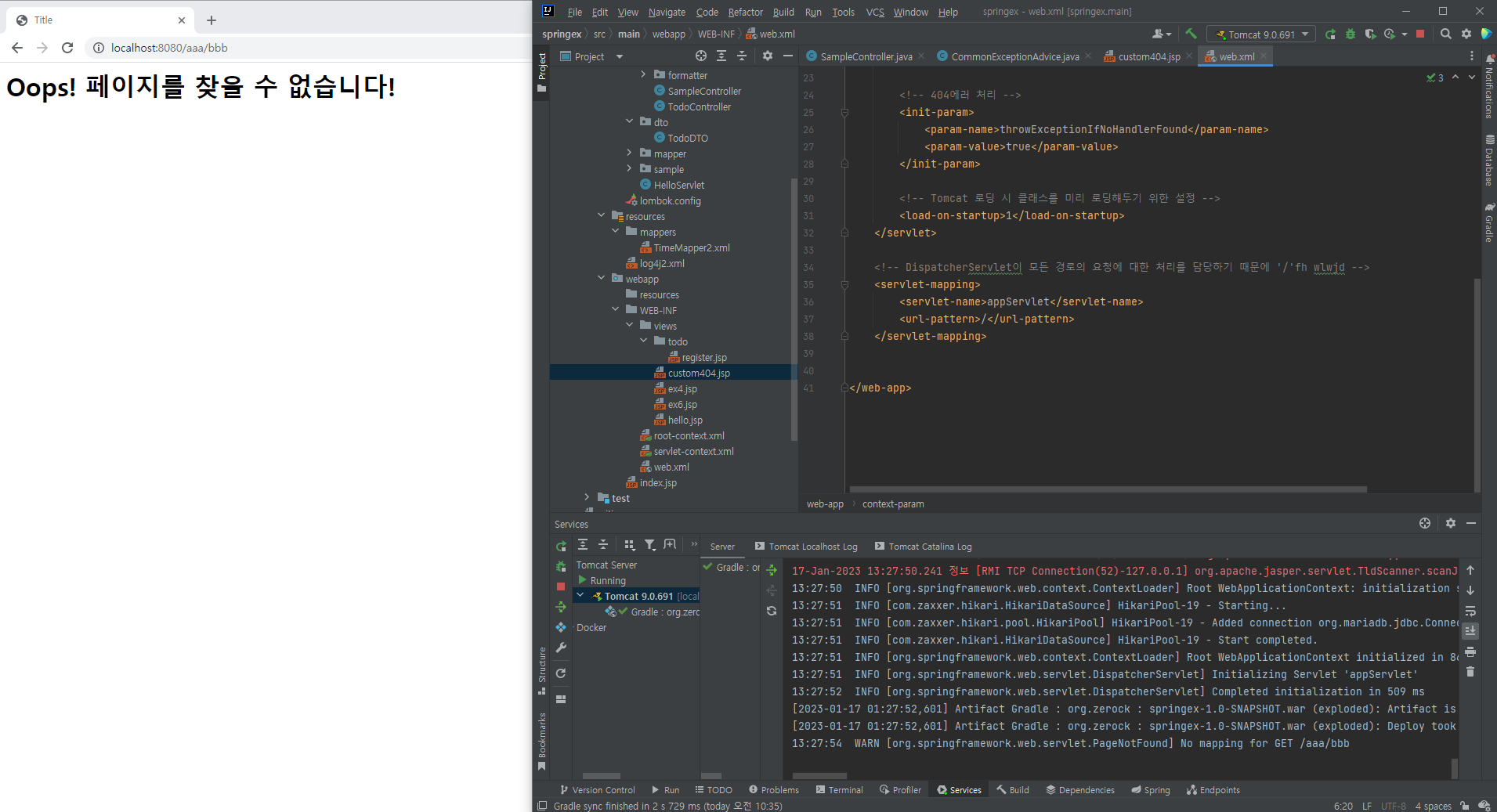
3) 404 에러 페이지와 @ResponseStatus
서버 내부가 아닌 시작부터 잘못된 URL을 호출할 때 404 예외 발생
@ControllerAdvice에 작성하는 메서드에 @ResponseStatus를 이용하면 404상태에 맞는 화면을 별도로 작성 가능
// CommonExceptionAdvice
package org.zerock.springex.controller.exception;
import ...
@ControllerAdvice
@Log4j2
public class CommonExceptionAdvice {
...
// 404 에러 대비
@ExceptionHandler(NoHandlerFoundException.class)
@ResponseStatus(HttpStatus.NOT_FOUND)
public String notFound() {
return "custom404";
}
}
custom404의 페이지를 jsp 파일로 작성
<!-- custom404 -->
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>Title</title>
</head>
<body>
<h1>Oops! 페이지를 찾을 수 없습니다!</h1>
</body>
</html>
web.xml에서는 DispatcherServlet의 설정을 조정해야함
<servlet> 태그 내에 <init-param>을 추가하고 throwExceptionIfNoHandlerFound라는 파라미터 설정 추가
- main > source > mappers 패키지 생성 > TimeMapper2.xml 파일 생성(파일 이름을 매퍼 인터페이스와 같게)
<!-- TimeMapper2.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace = "org.zerock.springex.mapper.TimeMapper2">
<!-- select의 id 속성값을 매터 인터페이스의 메서드 이름과 같게 설정 -->
<!-- select 태그는 반드시 resultType이나 resultMap 속성을 지정해야 함 -->
<!-- resultType은 select문이 결과를 어떤 타입으로 처리할 지에 대한 설정 -->
<select id = "getNow" resultType = "string">
select now()
</select>
</mapper>
- 마지막으로 root-context.xml 파일의 MyBatis 설정에 XML 파일들을 인식하도록 설정을 추가
<!-- root-context.xml -->
...
<bean id = "sqlSessionFactory" class = "org.mybatis.spring.SqlSessionFactoryBean">
<property name = "dataSource" ref = "dataSource" />
<!-- mapperLocations는 XML 매퍼 파일의 위치 -->
<property name = "mapperLocations" value = "classpath:/mappers/**/*.xml"></property>
</bean>
...
X, y = load_diabetes(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
model = SVR()
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.14990303611569455
평가 데이터 점수: 0.18406447674692128
SVM을 사용한 분류 모델(SVC)
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
model = SVC()
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9107981220657277
평가 데이터 점수: 0.951048951048951
1. 커널 기법
입력 데이터를 고차원 공간에 사상(Mapping)하여 비선형 특징을 학습할 수 있도록 확장
scikit-learn에서는 Linear, Polynomial, RBF(Radial Basis Function) 등 다양한 커널 기법 지원
위의 두 개는 Linear Kernel로, 직선으로 분류
아래는 RBF Kernel과 Polynomial Kernel로 비선형적으로 분류
# SVR에 대해 Linear, Polynomial, RBF Kernel 각각 적용
X, y = load_diabetes(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
linear_svr = SVR(kernel = 'linear')
linear_svr.fit(X_train, y_train)
print("Linear SVR 학습 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
print("Linear SVR 평가 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
polynomial_svr = SVR(kernel = 'poly')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVR 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVR 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
rbf_svr = SVR(kernel = 'rbf')
rbf_svr.fit(X_train, y_train)
print("RBF SVR 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVR 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
Linear SVR 학습 데이터 점수: -0.0029544543016808422
Linear SVR 평가 데이터 점수: -0.0029544543016808422
Polynomial SVR 학습 데이터 점수: 0.26863144203680633
Polynomial SVR 평가 데이터 점수: 0.26863144203680633
RBF SVR 학습 데이터 점수: 0.14990303611569455
RBF SVR 평가 데이터 점수: 0.14990303611569455
# SVC에 대해 Linear, Polynomial, RBF Kernel 각각 적용
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
linear_svr = SVC(kernel = 'linear')
linear_svr.fit(X_train, y_train)
print("Linear SVC 학습 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
print("Linear SVC 평가 데이터 점수: {}".format(linear_svr.score(X_train, y_train)))
polynomial_svr = SVC(kernel = 'poly')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVC 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVC 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
rbf_svr = SVC(kernel = 'rbf')
rbf_svr.fit(X_train, y_train)
print("RBF SVC 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVC 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
Linear SVC 학습 데이터 점수: 0.9694835680751174
Linear SVC 평가 데이터 점수: 0.9694835680751174
Polynomial SVC 학습 데이터 점수: 0.8990610328638498
Polynomial SVC 평가 데이터 점수: 0.8990610328638498
RBF SVC 학습 데이터 점수: 0.9107981220657277
RBF SVC 평가 데이터 점수: 0.9107981220657277
2. 매개변수 튜닝
SVM은 사용하는 Kernel에 따라 다양한 매개변수 설정 가능
매개변수를 변경하면서 성능 변화를 관찰
# SVC의 Polynomial Kernel 설정에서 매개변수를 더 변경
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
polynomial_svr = SVC(kernel = 'poly', degree = 2, C = 0.1, gamma = 'auto')
polynomial_svr.fit(X_train, y_train)
print("Polynomial SVC 학습 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
print("Polynomial SVC 평가 데이터 점수: {}".format(polynomial_svr.score(X_train, y_train)))
# 출력 결과
Polynomial SVC 학습 데이터 점수: 0.9765258215962441
Polynomial SVC 평가 데이터 점수: 0.9765258215962441
# SVC의 RBF Kernel 설정에서 매개변수를 더 변경
rbf_svr = SVC(kernel = 'rbf', C = 2.0, gamma = 'scale')
rbf_svr.fit(X_train, y_train)
print("RBF SVC 학습 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
print("RBF SVC 평가 데이터 점수: {}".format(rbf_svr.score(X_train, y_train)))
# 출력 결과
RBF SVC 학습 데이터 점수: 0.9131455399061033
RBF SVC 평가 데이터 점수: 0.9131455399061033
위에서 기본 매개변수로만 돌렸을 때 0.89정도로 나왔던 점수보다 더 높은 점수로, 매개변수를 조작함에 따라 성능이 더 높아짐을 확인
3. 데이터 전처리
SVM은 입력 데이터가 정규화 되어야 좋은 성능을 보임
주로 모든 특성 값의 범위를 [0, 1]로 맞추는 방법 사용
scikit-learn의 StandardScaler 또는 MinMaxScaler 사용해 정규화
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
# 스케일링 이전 데이터
model = SVC()
model.fit(X_train, y_train)
print("SVC 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVC 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVC 학습 데이터 점수: 0.9107981220657277
SVC 평가 데이터 점수: 0.951048951048951
# 스케일링 이후 데이터
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model.fit(X_train, y_train)
print("SVC 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVC 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVC 학습 데이터 점수: 0.9882629107981221
SVC 평가 데이터 점수: 0.972027972027972
4. 당뇨병 데이터로 SVR(커널은 기본값('linear')로) 실습
- 가장 기본 모델
# 데이터 불러오기
X, y = load_diabetes(return_X_y = True)
# 학습 / 평가 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# 범위 [0, 1]로 정규화
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 선형 SVR 모델에 피팅
model = SVR(kernel = 'linear')
model.fit(X_train, y_train)
# 점수 출력
print("SVR 학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("SVR 평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
SVR 학습 데이터 점수: 0.5114667038352527
SVR 평가 데이터 점수: 0.45041670810045853
# 하이퍼 파라미터에 kernel을 넣어 어떤 kernel이 가장 좋은 지 판단
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'rbf'))])
param_grid = [{'model__kernel': ['rbf', 'poly', 'sigmoid']}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# sigmoid가 가장 좋은 예측을 하는 것으로 나옴
# 커널은 sigmoid로 하고 나머지 하이퍼 파라미터 중 어떤 게 좋은지 GridSearch 실행
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVR(kernel = 'sigmoid'))])
param_grid = [{'model__gamma': ['scale', 'auto'],
'model__C': [1.0, 0.1, 0.01],
'model__epsilon': [1.0, 0.1, 0.01]}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_estimator_
# epsilon이 1.0, gamma는 auto일 때 가장 좋음
- 최종 sigmoid를 사용한 점수
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.3649291208855052
평가 데이터 점수: 0.39002165443861103
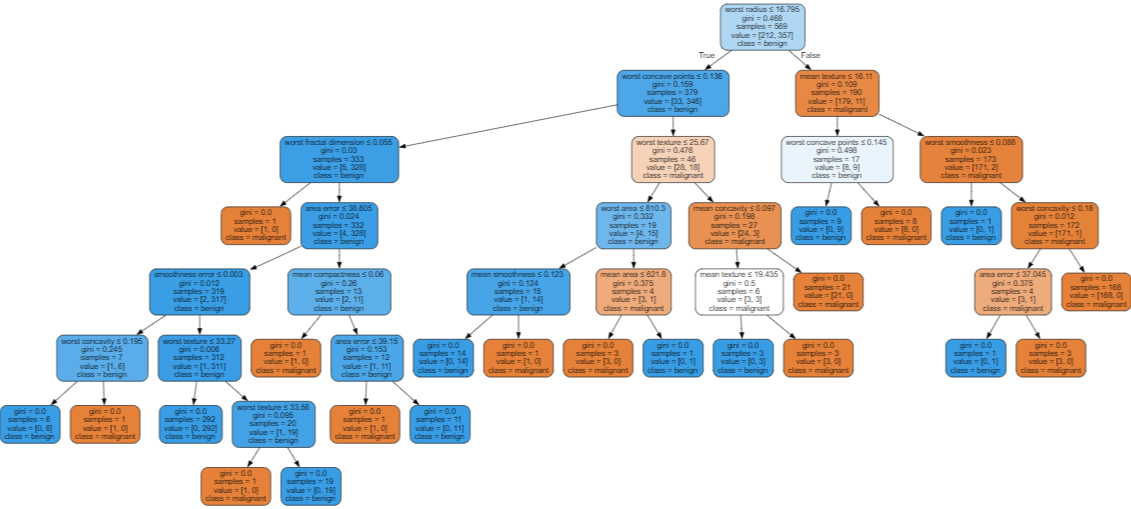
6. 유방암 데이터로 SVC(커널은 기본값('linear')로) 실습
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = SVC(kernel = 'linear')
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9846153846153847
평가 데이터 점수: 1.0
- 이미 잘 나오긴 함
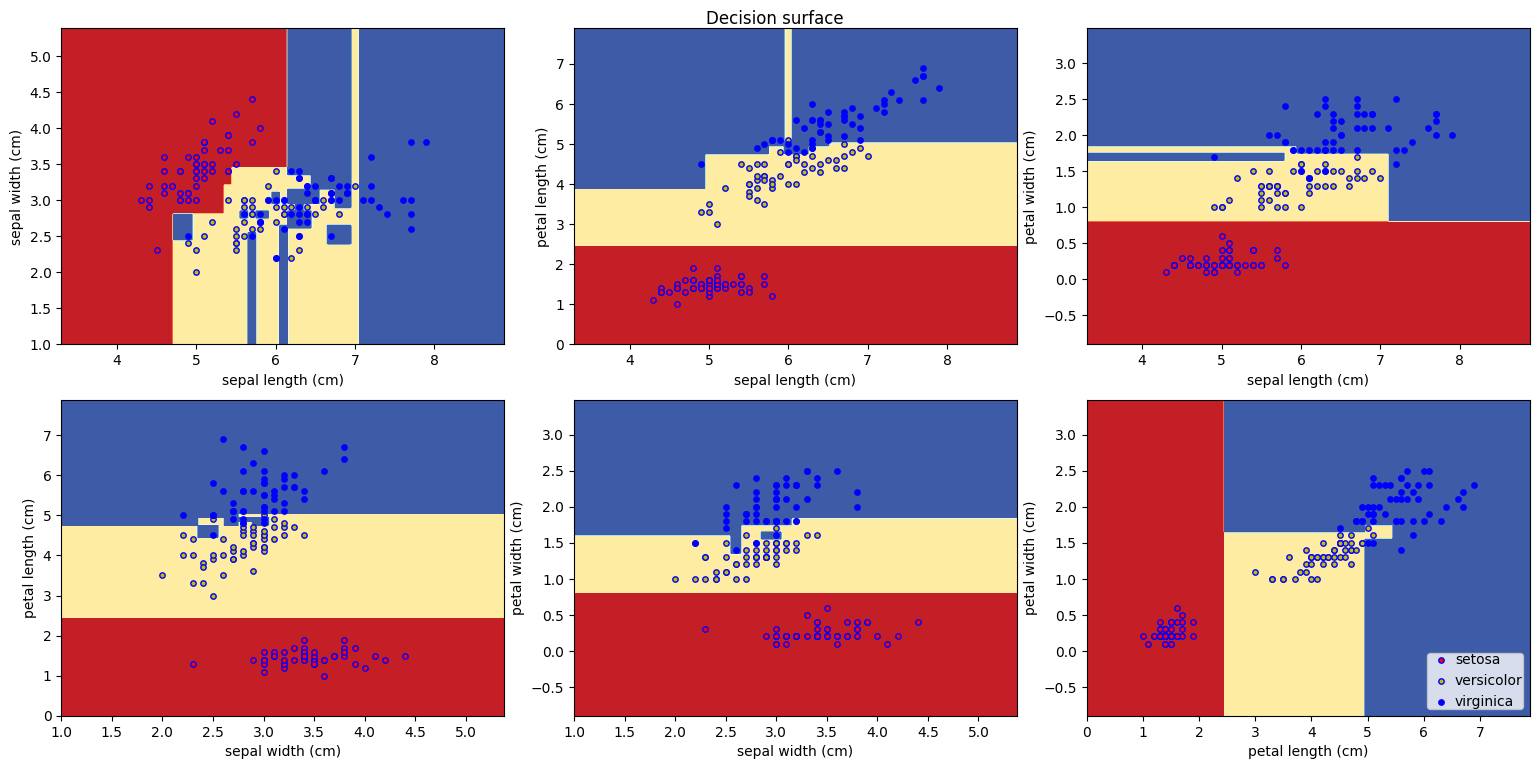
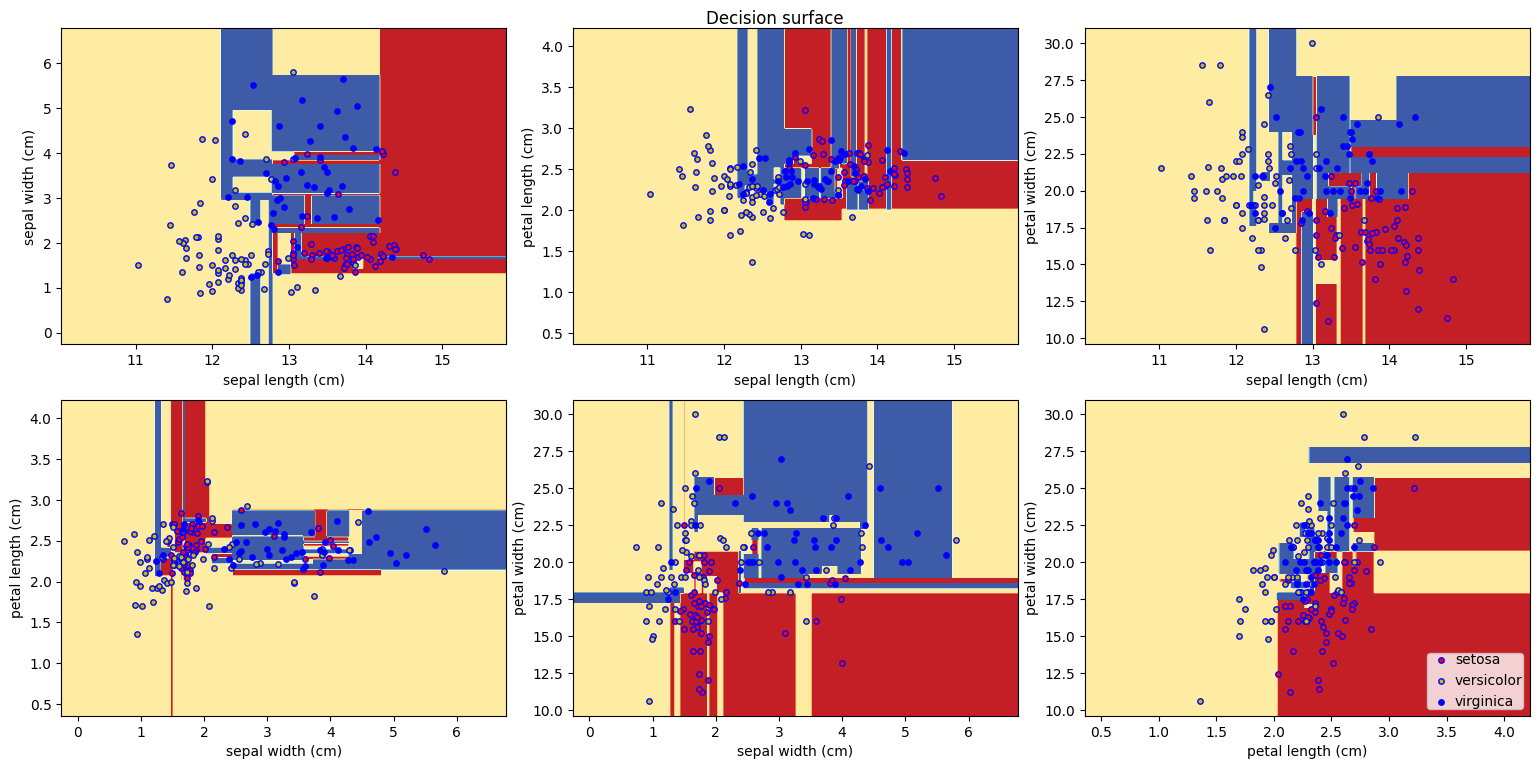
- 시각화
def make_meshgrid(x, y, h = 0.02):
x_min, x_max = x.min()-1, x.max()+1
y_min, y_max = y.min()-1, y.max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contour(clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = plt.contourf(xx, yy, Z, **params)
return out
X_comp = TSNE(n_components = 2).fit_transform(X)
X0, X1 = X_comp[:, 0], X_comp[:, 1]
xx, yy = make_meshgrid(X0, X1)
model.fit(X_comp, y)
plot_contour(model, xx, yy, cmap = plt.cm.coolwarm, alpha = 0.7)
plt.scatter(X0, X1, c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
- 거의 대부분 같은 색으로 맞춘 모습
# 교차 검증
estimator = make_pipeline(StandardScaler(), SVC(kernel = 'linear'))
cross_validate(
estimator = estimator,
X = X, y = y,
cv = 5,
n_jobs = multiprocessing.cpu_count(),
verbose = True
)
# 출력 결과
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 2 out of 5 | elapsed: 1.5s remaining: 2.3s
[Parallel(n_jobs=8)]: Done 5 out of 5 | elapsed: 1.5s finished
{'fit_time': array([0.00498796, 0.00498223, 0.00598669, 0.00300407, 0.00298858]),
'score_time': array([0.00199056, 0.00099754, 0.00099754, 0.00091267, 0.00099921]),
'test_score': array([0.96491228, 0.98245614, 0.96491228, 0.96491228, 0.98230088])}
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.978021978021978
평가 데이터 점수: 1.0
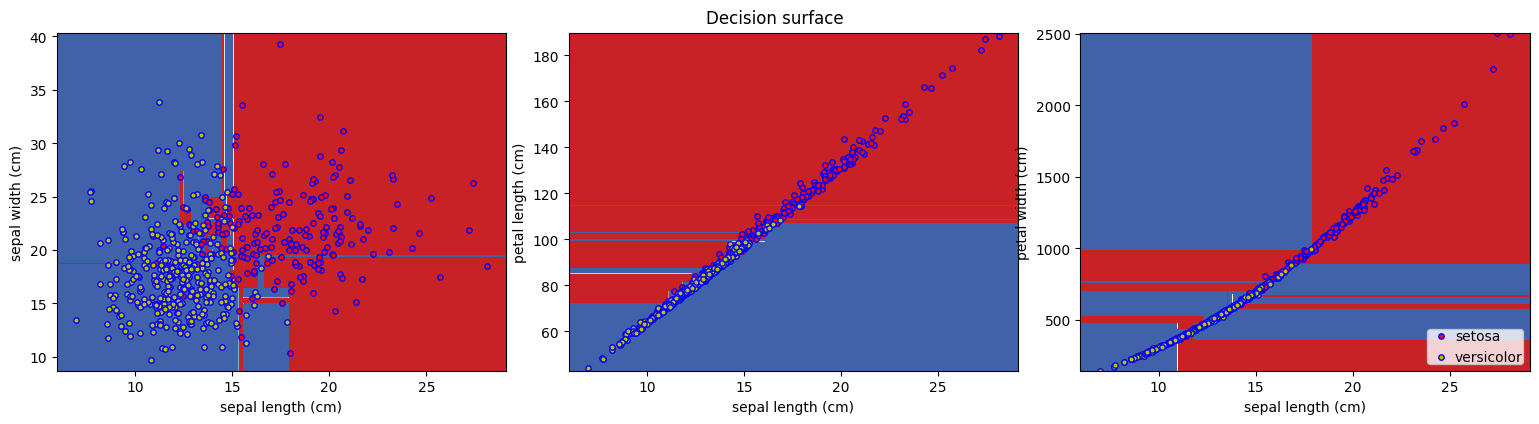
7. 유방암 데이터로 SVC(커널 변경) 실습
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = SVC(kernel = 'rbf')
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.989010989010989
평가 데이터 점수: 0.9385964912280702
def make_meshgrid(x, y, h = 0.02):
x_min, x_max = x.min()-1, x.max()+1
y_min, y_max = y.min()-1, y.max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contour(clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = plt.contourf(xx, yy, Z, **params)
return out
X_comp = TSNE(n_components = 2).fit_transform(X)
X0, X1 = X_comp[:, 0], X_comp[:, 1]
xx, yy = make_meshgrid(X0, X1)
model.fit(X_comp, y)
plot_contour(model, xx, yy, cmap = plt.cm.coolwarm, alpha = 0.7)
plt.scatter(X0, X1, c = y, cmap = plt.cm.coolwarm, s = 20, edgecolors = 'k')
- 커널이 linear일 때처럼 선형으로 나눠지지 않고 곡선으로 나눠짐
# 교차 검증
estimator = make_pipeline(StandardScaler(), SVC(kernel = 'rbf'))
cross_validate(
estimator = estimator,
X = X, y = y,
cv = 5,
n_jobs = multiprocessing.cpu_count(),
verbose = True
)
# 출력 결과
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 2 out of 5 | elapsed: 1.6s remaining: 2.5s
[Parallel(n_jobs=8)]: Done 5 out of 5 | elapsed: 1.6s finished
{'fit_time': array([0.0039866 , 0.00697613, 0.00698733, 0.0039866 , 0.00399065]),
'score_time': array([0.00299096, 0.00299168, 0.00397682, 0.00300074, 0.0019927 ]),
'test_score': array([0.97368421, 0.95614035, 1. , 0.96491228, 0.97345133])}
# GridSearch
pipe = Pipeline([('scaler', StandardScaler()),
('model', SVC())])
param_grid = [{'model__kernel': ['rbf', 'poly', 'sigmoid']}]
gs = GridSearchCV(
estimator = pipe,
param_grid = param_grid,
n_jobs = multiprocessing.cpu_count(),
cv = 5,
verbose = True
)
gs.fit(X, y)
gs.best_params_
# 출력 결과
{'model__kernel': 'rbf'}
# kernel이 rbf일 때 가장 좋은 성능
model = gs.best_estimator_
model.fit(X_train, y_train)
print("학습 데이터 점수: {}".format(model.score(X_train, y_train)))
print("평가 데이터 점수: {}".format(model.score(X_test, y_test)))
# 출력 결과
학습 데이터 점수: 0.9372487007252107
평가 데이터 점수: 0.8063011852114969
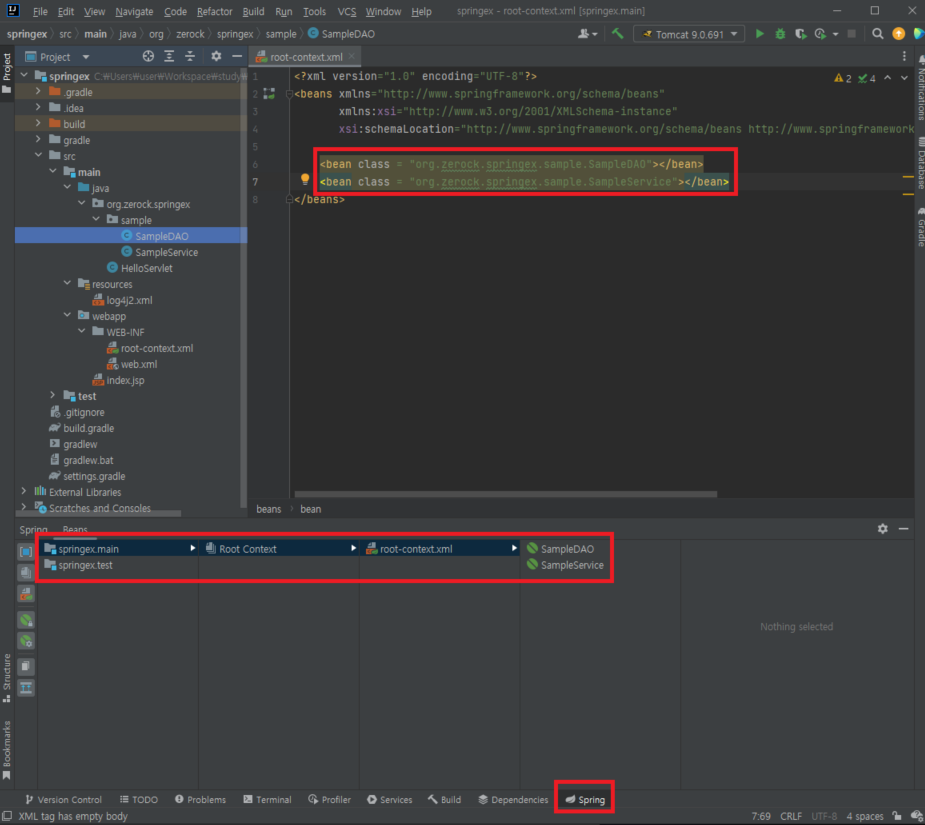
- SampleDAO 인터페이스는 실체가 없기 때문에 SampleDAO 인터페이스를 구현한 클래스를 SampleDAOImpl이라는 이름으로 선언
// SampleDAOImpl
package org.zerock.springex.sample;
import org.springframework.stereotype.Repository;
// @Repository를 이용해서 해당 클래스의 객체를 스프링의 Bean으로 처리하도록 구성
@Repository
public class SampleDAOImpl implements SampleDAO{
}
- SampleService 입장에서는 인터페이스만 바라보고 있기 때문에 실제 객체가 SampleDAOImpl의 인스턴스인지 알 수 없지만, 코드 작성에 문제 x
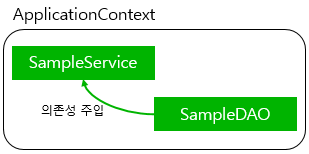
- 느슨한 결합: 객체와 객체의 의존 관계의 실제 객체를 몰라도 가능하게 하는 방식
- 느슨한 결합을 이용하면 나중에 SampleDAO 타입의 객체를 다른 객체로 변경해도 SampleService 타입을 이용하는 코드를 수정할 일이 없어 더 유연한 구조임
- 다른 SampleDAO 객체로 변경해보기(특정 기간에만 SampleDAO를 다른 객체로 변경해야 하는 경우 생각)
- EventSampleDAOImpl 클래스 작성
// EventSampleDAOImpl
package org.zerock.springex.sample;
import org.springframework.stereotype.Repository;
@Repository
public class EventSampleDAOImpl implements SampleDAO{
}
- SampleService에 필요한 SampleDAO 타입의 Bean이 두 개(SampleDAOImpl, EventSampleDAOImpl)이므로, 어떤걸 주입해야 할 지 모르게 됨
- Test 실행 시, 스프링이 SampleDAO 타입의 객체가 하나이길 기대했지만 2개가 발견됐다는 오류 출력
- 해결 방법으로 두 클래스 중 하나를 @Primary라는 어노테이션으로 지정(지금 사용하고 싶은 것에 지정)
// EventSampleDAO
package org.zerock.springex.sample;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Primary;
import org.springframework.stereotype.Repository;
@Repository
@Primary
public class EventSampleDAOImpl implements SampleDAO{
}
- Test 실행 시, 정상적으로 EventSampleDAOImpl이 주입된 것을 확인
- Qualifier 이용하기
- @Primary 이용하는 방법 이외에 @Qualifier를 이용하여 이름을 지정해서 특정한 이름의 객체 주입
- Lombok과 @Qualifier를 같이 이용하기 위해 src/main/java 폴더에 lombok.config 파일 생성
// SampleDAOImpl
@Repository
// @Qualifier를 이용해서 SampleDAOImpl에 'normal'이라는 이름 지정
@Qualifier("normal")
public class SampleDAOImpl implements SampleDAO{
}
// EventSampleDAOImpl
@Repository
// @Qualifier를 이용해서 EventSampleDAOImpl에 'event'라는 이름 지정
@Qualifier("event")
public class EventSampleDAOImpl implements SampleDAO{
}
- SampleService에서 @Qualifier를 이용해 이름을 지정하면 해당 이름의 SampleDAO 객체를 사용
// SampleService
package org.zerock.springex.sample;
import lombok.RequiredArgsConstructor;
import lombok.ToString;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
@Service
@ToString
@RequiredArgsConstructor
public class SampleService {
@Qualifier("normal")
private final SampleDAO sampleDAO;
}
SampleService에서 @Qualifier의 이름을 normal로 지정했을 때 SampleDAOImpl을 사용
// SampleService
package org.zerock.springex.sample;
import lombok.RequiredArgsConstructor;
import lombok.ToString;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
@Service
@ToString
@RequiredArgsConstructor
public class SampleService {
@Qualifier("event")
private final SampleDAO sampleDAO;
}
SampleService에서 @Qualifier의 이름을 event로 지정했을 때 EventSampleDAOImpl을 사용
- 스프링의 Bean으로 지정되는 객체들
- 스프링의 모든 클래스의 객체가 Bean으로 처리되는 것은 x
- 스프링의 Bean으로 등록되는 객체들은 '핵심 배역'을 하는 객체(오랜 시간 프로그램에 상주하며 중요한 역할을 하는 '역할 중심' 객체
- DTO나 VO 등 '역할'보다 '데이터' 중심으로 설계된 객체들은 스프링의 Bean으로 등록되지 않음(특히 DTO는 생명주기가 짧고 데이터 보관이 주된 역할이어서 Bean으로 처리 x)
- XML이나 어노테이션으로 처리하는 객체
- Bean으로 처리할 때 XML 설정을 이용할 수도 있고 어노테이션을 처리할 수도 있음
- 판단 기준은 '코드를 수정할 수 있는가'
- jar 파일로 추가되는 클래스의 객체를 Bean으로 처리해야 하면, 해당 코드가 존재하지 ㅇ낳아 어노테이션을 추가할 수 없어, XML에서 <bean>을 사용해 처리
- 직접 작성되는 클래스는 어노테이션을 이용
4. 웹 프로젝트를 위한 스프링 준비
Bean을 담은 ApplicationContext가 웹 애플리케이션에서 동작하려면, 웹 애플리케이션이 실행될 때 스프링을 로딩해서 해당 웹 애플리케이션 내부에 스프링의 ApplicationContext를 생성하는 작업 필요
web.xml을 이용해서 리스너를 설정
web.xml 설정 이전에, 스프링 프레임워크의 웹 관련 작업은 spring-webmvc 라이브러리를 추가해야 설정 가능
ServletContextEvent를 이용하면 현재 애플리케이션이 실행되는 공간인 ServletContext에 접근 가능
ServletContext는 현재 웹 애플레케이션 내 모든 자원들을 같이 사용하는 공간
이 공간에 무언가를 저장하면 모든 Controller나 JSP 등에서 이를 활용 가능
ServletContext에는 setAttribute()를 이용해서 원하는 이름으로 객체를 보관할 수 있음
다음과 같이 'appName'이라는 이름으로 'W2'라는 이름을 지정하면, EL에서 ${appName}으로 이를 이용 가능
// W2AppListener에서 setAttribute()를 통해 객체를 생성
package org.zerock.w2.listener;
import lombok.extern.log4j.Log4j2;
import javax.servlet.ServletContext;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import javax.servlet.annotation.WebListener;
@WebListener
@Log4j2
public class W2AppListener implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent sce) {
log.info("-----------------init-----------------");
log.info("-----------------init-----------------");
log.info("-----------------init-----------------");
// 시작과 함께 객체 생성
ServletContext servletContext = sce.getServletContext();
servletContext.setAttribute("appName", "W2");
}
...
}
// TodoListController에서 다음과 같이 객체 활용 가능
package org.zerock.w2.controller;
...
@WebServlet(name = "todoListController", value = "/todo/list")
@Log4j2
public class TodoListController extends HttpServlet {
private TodoService todoService = TodoService.INSTANCE;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
log.info("todo list.................");
// getServletContext() 메서드를 이용해 ServletContext를 이용할 수 있음
ServletContext servletContext = req.getServletContext();
log.info("appName: " + servletContext.getAttribute("appName"));
...
}
}
<!-- list.jsp에 다음과 같이 EL 구문을 추가하면 화면에서 나타내는 용도로 사용가능 -->
<body>
<h1>Todo List</h1>
<!-- appName이라는 이름을 가진 객체(W2)를 호출 -->
<h2>${appName}</h2>
<h2>${loginInfo}</h2>
<h3>${loginInfo.mname}</h3>
...
</body>
${appName}을 입력하여, appName을 이름으로 하는 객체 "W2"를 출력
ServletContextListener와 스프링 프레임워크
ServletContextListener와 ServletContext를 이용하면 프로젝트 실행 시 필요한 객체들을 준비하는 작업 처리 가능
커넥션 풀 초기화 또는 TodoService 같은 객체 미리 생성해서 보관 등
특히, 스프링 프레임워크에서 웹 프로젝트를 미리 로딩하는 작업을 처리할 때 ServletContextListener 이용
실습
2) 세션 관리 리스너
- Servlet의 리스너 중 HttpSession 관련 작업을 감시하는 리스너 등록 가능
(HttpSessionListener나 HttpSessionAttributeListener 등)
- 이를 이용해서 HttpSession이 생성되거나 setAttribute() 등의 작업이 이루어질 때를 감지 가능
- listener 패키지에 LoginListener 클래스 추가
// LoginListener
package org.zerock.w2.listener;
import lombok.extern.log4j.Log4j2;
import javax.servlet.annotation.WebListener;
import javax.servlet.http.HttpSessionAttributeListener;
import javax.servlet.http.HttpSessionBindingEvent;
@WebListener
@Log4j2
public class LoginListener implements HttpSessionAttributeListener {
@Override
public void attributeAdded(HttpSessionBindingEvent event) {
// 이름과 객체의 값들을 받아옴
String name = event.getName();
Object obj = event.getValue();
if(name.equals("loginIndo")) {
log.info("A user logined.........");
log.info(obj);
}
}
}
로그인 실행 시 로그에 위의 메세지가 출력됨
- LoginListener는 HttpSessionAttributeListener 인터페이스를 구현
- HttpSessionAttributeListener 인터페이스는 attributeAdded(), attributeRemoved(), attributeReplaced() 를 이용해서, HttpSession에 setAttribute() / removeAttribute() 등의 작업을 감지